

在数字化工作流程中,有效管理大量PDF文件是一项常见的挑战。面对成千上万的文档,如何高效、准确地提取并整理这些文件的名称成为了不可或缺的需求。传统的手动复制粘贴方式不仅效率低下,还容易导致错误累积,这无疑增加了工作人员的工作负担。
为了解决这一问题,多种专业工具应运而生,旨在简化这一过程。接下来将介绍几种专业的批量提取PDF文件名的方法,以帮助您更好地实现文档管理和自动化处理。

方案一:使用“汇帮文件名提取器”高效提取大量PDF文件名称
使用汇帮文件名提取器批量处理PDF文件名的步骤指南
1. 启动软件并选择功能
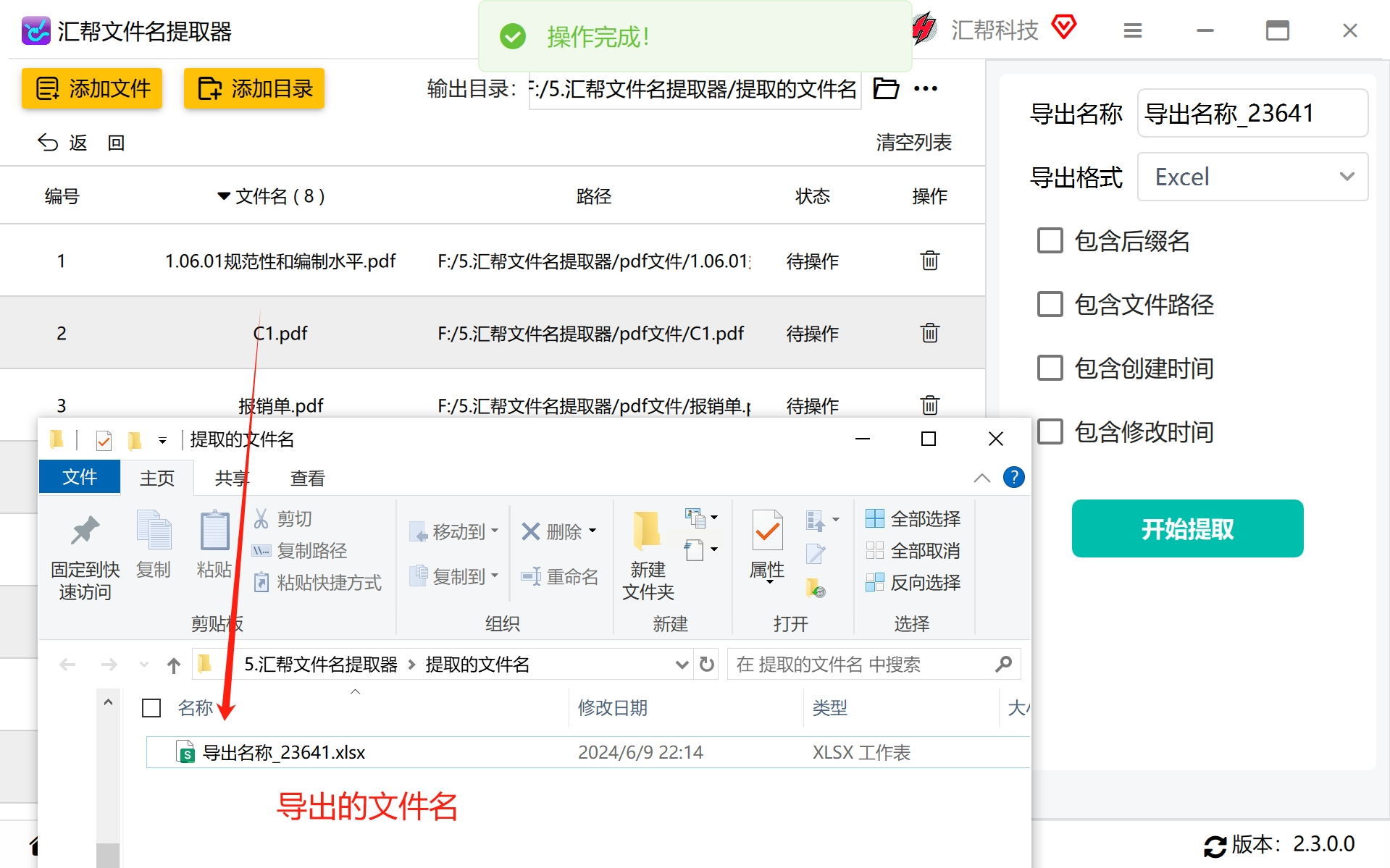
启动已经成功安装的最新版本的【汇帮文件名提取器】。在主界面上,找到并点击“文件名提取”功能选项,因为我们需要批量处理目录中的PDF文件名。
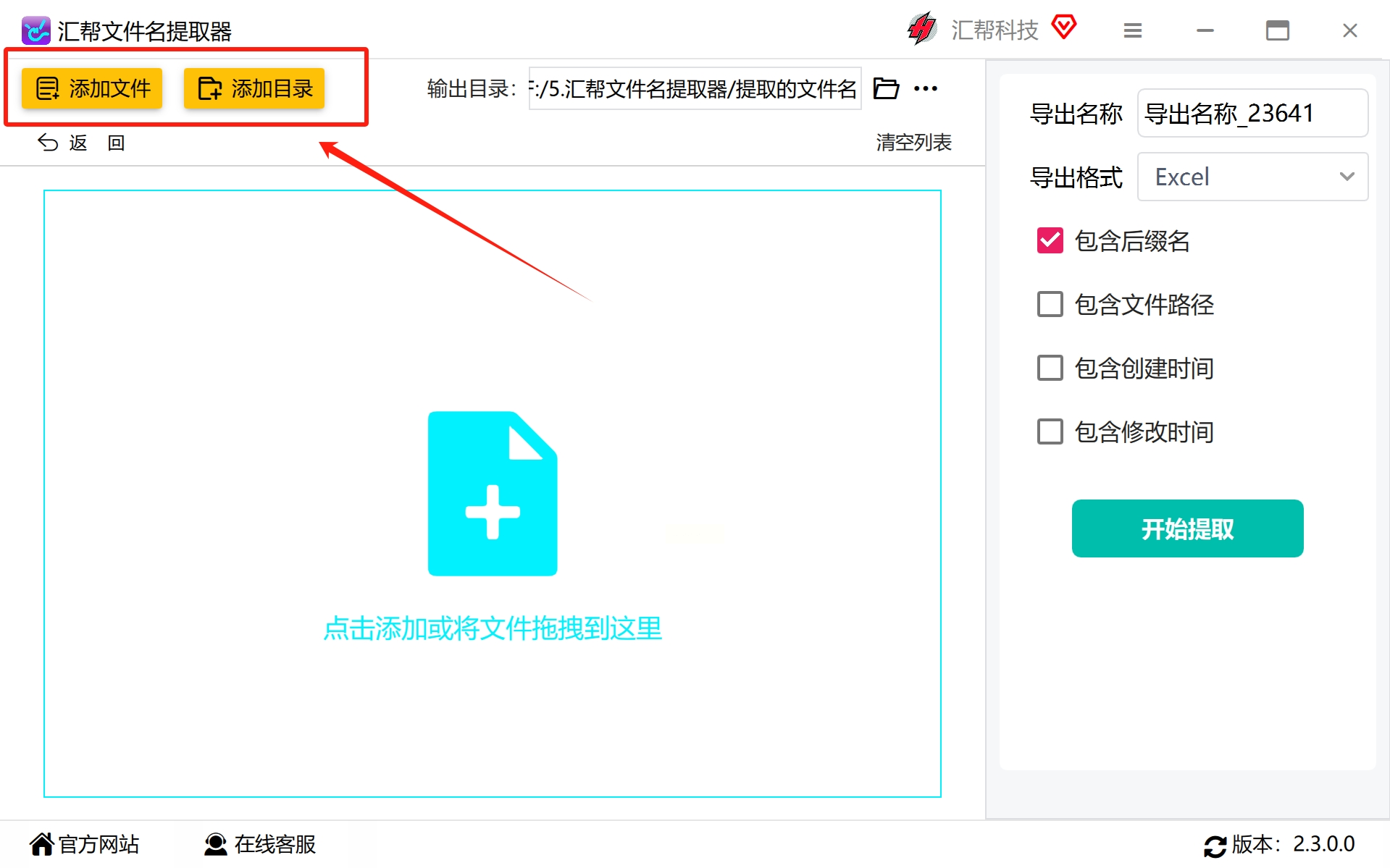
2. 添加文件和目录
通过点击“添加文件”或“添加目录”按钮,从需要提取信息的PDF文件所在位置选择所需的文件或将整个目录拖入软件中。这样可以实现批量处理,且不设文件数量上限。
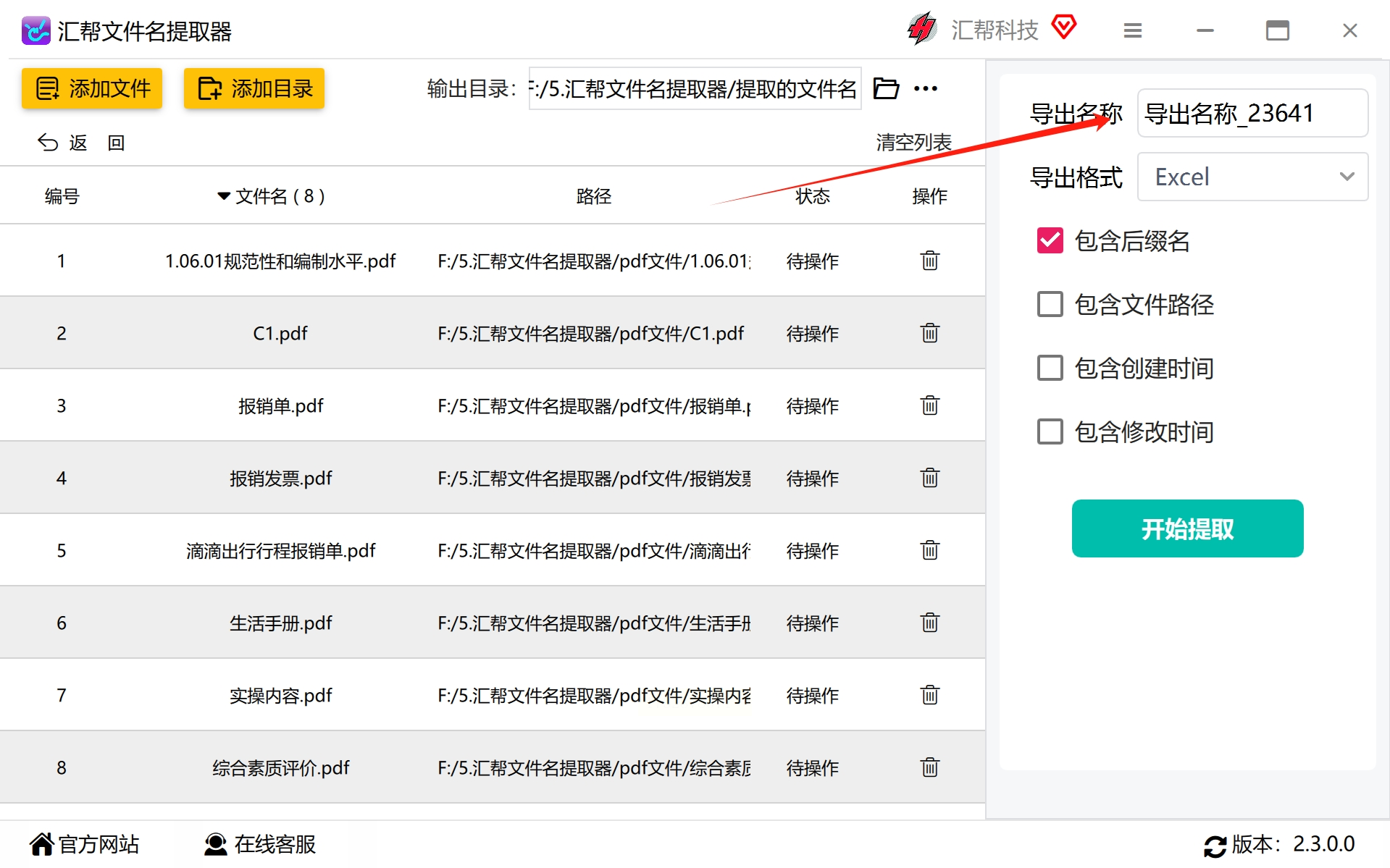
3. 设置导出名称与格式
在设置页面中输入你希望用于保存提取结果的命名规则或直接保持默认值。接下来,在“导出”选项卡中,选择你更偏好的文件类型(如Excel、CSV或TXT)。这里我们选择了Excel作为导出格式。

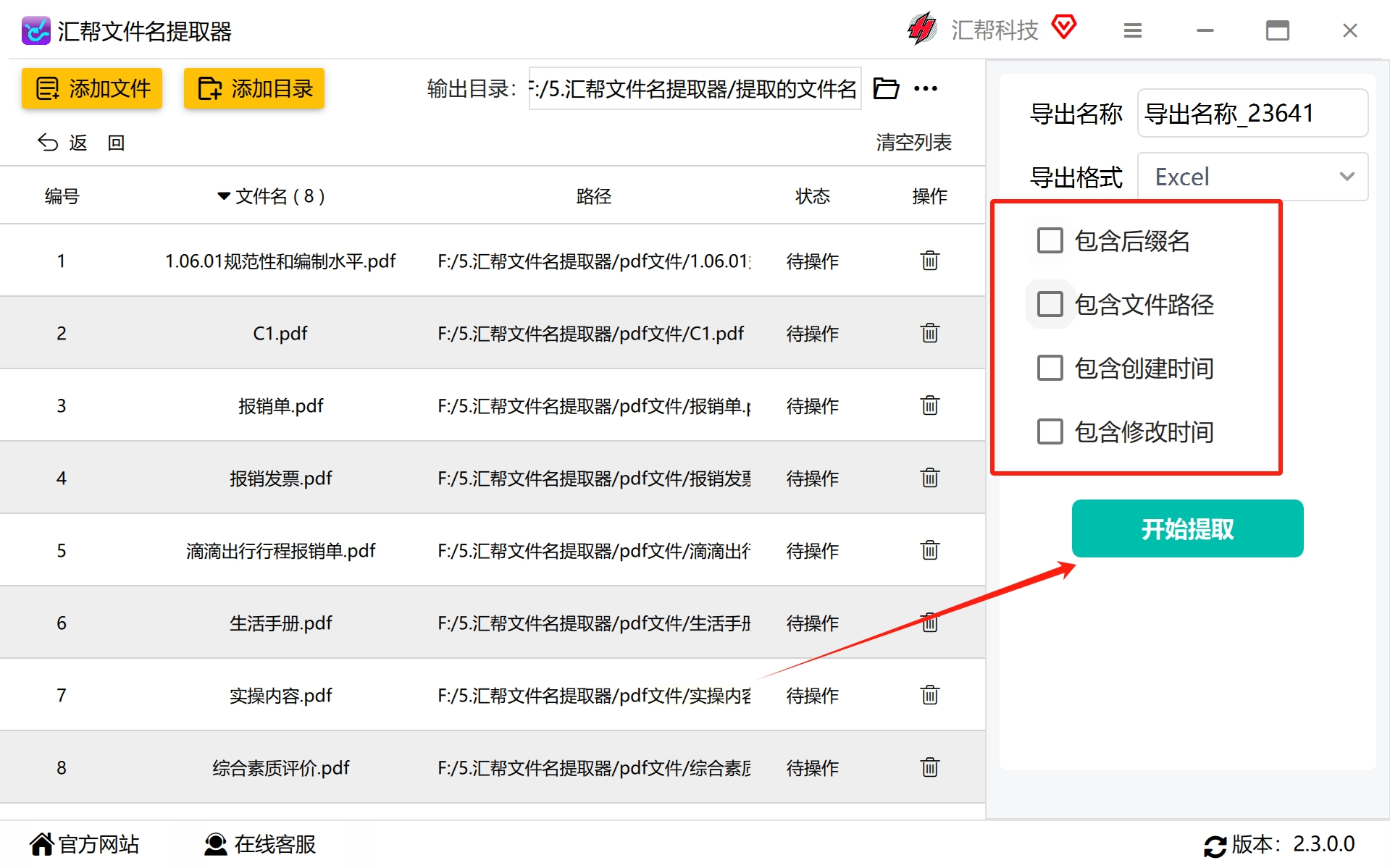
4. 配置其他选项并开始处理
根据实际需要调整其他设置项,例如是否提取文件后缀名、路径及创建/修改时间等信息。完成配置后点击“开始提取”按钮启动整个过程。
5. 完成与检查结果
系统会给出操作完成的提示。此时,在指定的输出路径中查找并打开生成的文件即可查看所有PDF文件名。
通过以上步骤,你已经成功使用了汇帮文件名提取器来处理了一系列PDF文档的信息。这些信息可以直接复制用于报告撰写或其他项目需求上,极大提高了工作效率。这种方法简洁高效且易于操作,非常适合需要批量管理大量PDF文件的专业人士和团队。
方案二:小船文件名批量处理器
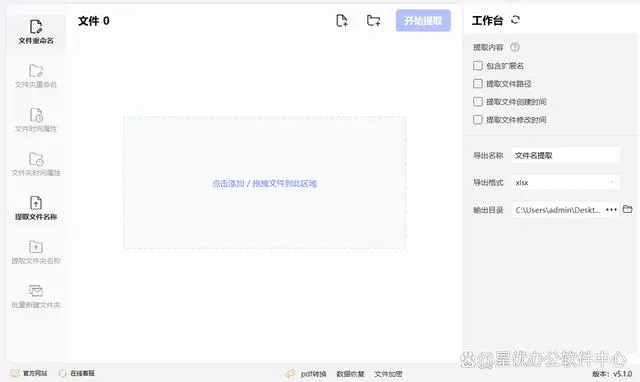
首先,在您的电脑桌面上找到并双击“小船文件名批量处理器”的图标,以启动此软件。接下来,在左侧的功能栏中点击“提取文件名称”按钮,进入具体功能界面。
第二步是导入您需要处理的PDF文档。您可以选择两种方式:点击界面上的“添加文件”,或者直接将PDF文件拖拽至相应区域。确认所有文件已成功加入后,请继续下一步操作。
接下来,设置提取内容选项。在软件右侧的“提取内容”区域中,通常情况下,默认设置已经能够满足需求,只需勾选默认选项即可开始处理文件名。
在完成设置之后,您需要指定导出的具体信息。在软件的下方位置输入您希望保存的Excel文件名称,并选择合适的输出格式——建议选择“xlsx”,这是最常用的Excel表格存储方式之一。
确认所有设置无误后,点击界面上的“开始提取”按钮。此过程可能需要一定时间,请耐心等待直至处理完成。
最后一步是查看提取结果。软件通常会提示您提取已成功,并提供一个快捷方式打开文件夹的位置。点击这一选项,将打开存储有提取结果Excel文件的路径。此时,您可以双击该文件进行浏览,发现所有PDF文件名已被准确无误地记录在内。
通过上述步骤的操作,“小船文件名批量处理器”软件便可以轻松完成对多份PDF文档名称的批量提取工作。
方案三:Windows PowerShell 命令的应用与实践
在Windows系统中,想要批量提取某个文件夹下所有PDF文件的名称?使用PowerShell工具可以轻松实现这一目标。本文将详细介绍如何利用内置命令Get-ChildItem与Select-Object来完成此操作,并通过输出到一个文本文件来保存这些名称。
首先,请确保你的系统安装了Windows PowerShell。在开始之前,你需要知道要处理的PDF文件所在的文件夹路径。例如,假设所有需要提取名称的PDF文件都位于“C:\Users\YourName\PdfDocuments”这个目录中。
接下来是具体的步骤:
1. 打开PowerShell:你可以通过点击开始菜单或任务栏上的搜索框,输入"PowerShell",然后在结果中选择管理员权限的版本来启动PowerShell。确保以管理员身份运行,以便有足够的权限访问文件夹。
2. 编写脚本:
- 在PowerShell窗口中输入以下命令,并根据实际情况修改路径:
```powershell
$pdfDirectory = "C:\Users\YourName\PdfDocuments"
$pdfFilenames = Get-ChildItem -Path $pdfDirectory -Filter "*.pdf" -File | Select-Object -ExpandProperty Name
```
这行命令中,“$pdfDirectory”是你的PDF文件所在的路径,`Get-ChildItem`用于获取该目录下的所有项,并筛选出扩展名为`.pdf`的文件。`Select-Object -ExpandProperty Name`则是用来从这些文件信息中提取出文件名。
3. 输出文件名:
- 为了将提取到的所有PDF文件名称保存在文本文件中,可以在PowerShell中添加以下命令:
```powershell
$pdfFilenames | Out-File "C:\Users\YourName\PdfDocuments\pdf_filenames.txt"
```
这一步会创建一个名为`pdf_filenames.txt`的文件,并将所有PDF文件名称写入其中。如果希望指定其他路径,可以在Out-File命令中调整路径。
完成以上步骤后,你可以通过文本编辑器打开“C:\Users\YourName\PdfDocuments\pdf_filenames.txt”,查看提取的所有PDF文件名列表。这种批量处理方法既高效又便捷,非常适合需要快速整理大量文件名称的情况。
方案四:Python脚本实现批量数据提取方法研究与应用
当面对大量PDF文件的管理需求时,使用Python来批量提取并列出这些文件名会是一项非常实用的操作。下面将详细介绍如何通过编写简单的Python脚本来实现这一目标。
步骤一:准备环境与工具
首先,确保你的开发环境中已经安装了Python。对于初学者来说,推荐选择最新版本的3.x系列(如3.9或更高)。同时,确认已正确设置了Python环境变量,并能够顺利打开Python命令行窗口进行脚本编写。
步骤二:导入必要的模块
接下来,你需要使用`os`和`fnmatch`这两个标准库来帮助完成文件遍历与匹配任务。在脚本开始时,通过以下代码引入它们:
```python
import os
import fnmatch
```
步骤三:定义目标目录及模式
指定你希望从中提取PDF文件名的目录路径,并使用通配符`*.pdf`来匹配所有PDF文件。将`/path/to/your/pdf/folder`替换为实际需要处理的文件夹路径:
```python
target_directory = '/path/to/your/pdf/folder'
pattern = '*.pdf'
```
步骤四:编写遍历与筛选逻辑
使用递归函数`os.walk()`来遍历指定目录及其子目录中的所有文件,并通过`fnmatch.fnmatch`判断是否匹配`.pdf`模式:
```python
def find_pdf_files(directory, pattern):
for root, dirs, files in os.walk(directory):
for basename in files:
if fnmatch.fnmatch(basename.lower(), pattern.lower()):
filename = os.path.join(root, basename)
print(filename)
find_pdf_files(target_directory, pattern)
```
步骤五:运行脚本
保存上述代码为一个`.py`文件,例如命名为`extract_pdfs.py`。在命令行中输入`python extract_pdfs.py`来执行脚本。

通过以上步骤,你便可以轻松地批量提取并打印指定文件夹及其子目录中的所有PDF文件名了。此方法不仅适用于个人文档管理,也可扩展应用于公司内部资料整理等场景。
方案五:批量提取文件命令行操作指南
通过命令行批量复制PDF文件名到Excel
如果你有大量PDF文件并希望将它们的名称导出到Excel中以便进一步分析或管理,你可以使用命令行工具来实现这一目标。以下是具体步骤。
1. 打开命令提示符
- 按下`Win + R`组合键,输入 `cmd` 并按回车键以打开命令提示符窗口。
2. 导航至包含PDF文件的目录
- 使用`cd`(更改目录)命令切换到你存放这些PDF文件的具体位置。例如:
```shell
cd C:\Users\YourUsername\PdfFolder
```
3. 生成PDF文件名列表并保存为文本文件
- 通过运行以下命令,可将当前文件夹下的所有PDF文件名称以纯文本形式导出至一个名为`filenames.txt`的文件中:
```shell
dir /b *.pdf > filenames.txt
```
- 此操作会创建一个包含所有PDF文件名的列表。
4. 使用Excel导入生成的文本文件
1. 启动Microsoft Excel并打开一个新的工作簿。
2. 转到“数据”选项卡,点击“从文本/CSV”以启动文本导入向导。
3. 浏览找到并选择之前创建的`filenames.txt`文件。
4. 确保在导入向导中选择了正确的分隔符(通常无需设置),然后继续导入过程。
5. 查看结果
- 导入完成后,你将能在Excel工作表中看到所有PDF文件名。你可以对这些数据进行进一步的操作和分析,如排序、筛选或使用公式来处理信息等。
在处理大量PDF文档时,快速批量提取文件名是提高工作效率的关键一步。本文总结了几种实用的方法和技术,帮助用户轻松管理文档库,无论是采用现成工具还是自定义脚本,都应注重数据的安全性和隐私保护,确保敏感信息在处理过程中不被泄露。同时,在实际应用中还需结合具体需求灵活选择合适的方法,以实现高效、安全的数据管理与处理。这些方法的综合运用能够帮助用户大幅提升工作效率,更好地应对日常工作中的挑战。
