

想象一下这样的场景:你收到一份包含100多页的OFD格式通知文件,需要从中提取某几个重要章节单独使用;或者在学习时,需要把PDF格式的课件转换成OFD格式后,每页单独保存用于复习;又或者团队协作中,需要把一份大型OFD报告拆分成单页发给不同成员处理。这些情况下,手动翻页复制显然效率低下,而掌握页面分割技巧就能轻松解决这些问题。
无论是职场新人处理公文流转,还是学生整理学习资料,拆分OFD页面都能让文档管理变得更加灵活。当你需要单独发送某几页内容时,无需再传输整个大文件,节省存储空间和传输时间;当你需要对文档进行局部修改时,拆分后的单页文件更容易编辑和管理。因此,掌握拆分OFD页面方法是提升办公效率的实用技能。

OFD页面怎么拆成分单页?这3个拆分OFD页面的方法快收好!
方法一:使用汇帮OFD转换器
详细步骤
1. 启动软件,找到核心功能入口
首先在电脑上打开汇帮OFD转换器。启动后你会看到一个简洁的主界面,顶部通常有几个核心功能选项,比如“OFD文件处理”、“格式转换”等。这里我们需要点击“OFD工具集”或者直接在功能区找到“页面分割”相关的按钮。对于经常使用OFD文件的用户来说,这个入口通常会在首页的显眼位置,方便快速访问。
2. 选择分割功能并添加文件
点击进入分割功能界面后,你会看到左侧有一个功能列表,其中“OFD分割”选项会被高亮显示。接下来需要添加待处理的OFD文件,有两种方式:一是直接将文件从电脑文件夹拖拽到软件的文件区域,二是点击“添加文件”按钮手动选择。如果需要处理多个文件,支持一次性添加多个,这对于批量处理多个文档非常方便。
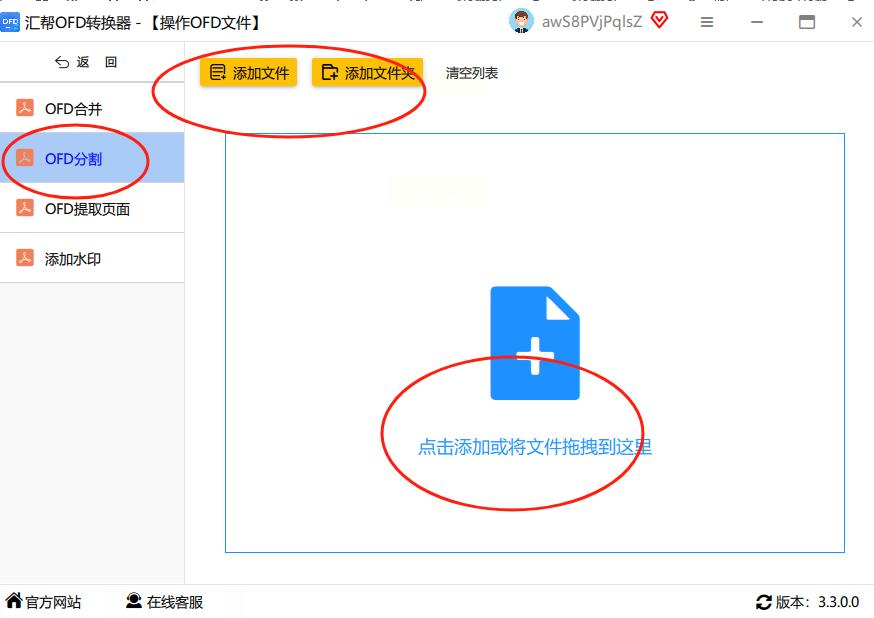
3. 预览文档并设置分割范围
文件添加成功后,软件会自动生成文档的缩略图预览。在这个界面中,你可以清晰地看到每一页的内容和页码。接下来需要设置分割范围:点击“页码选择”或“页面范围”按钮,会弹出一个选择窗口,这里你可以选择要保留的页面。
对于单页选择,可以直接点击目标页码;对于连续页面,可以按住鼠标左键拖动选择;如果是零散页面,还可以按住Ctrl键逐个点击。
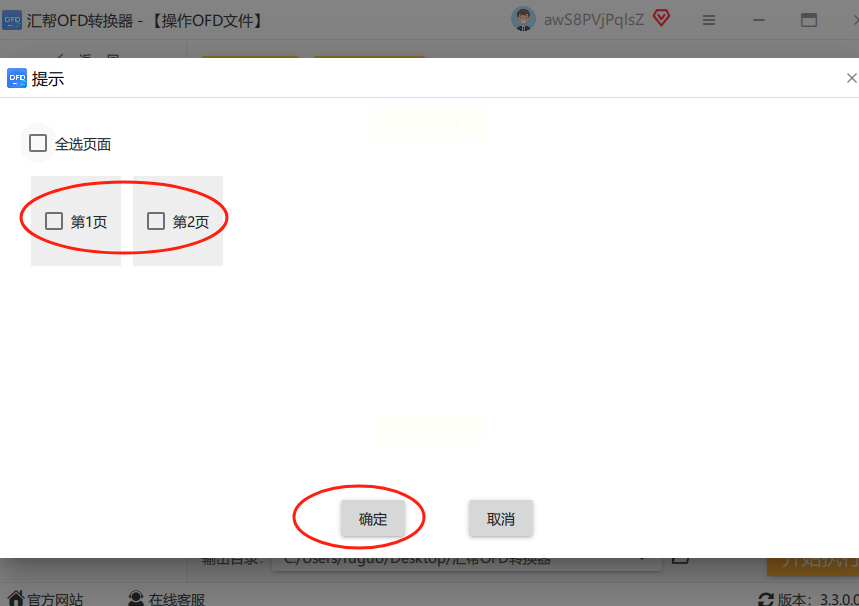
4. 选择输出位置与命名规则
设置好需要分割的页面后,最重要的一步是指定输出位置。在软件界面下方,通常有“输出目录”设置项,点击“浏览”按钮选择你希望保存拆分后文件的文件夹,
5. 开始转换并验证结果
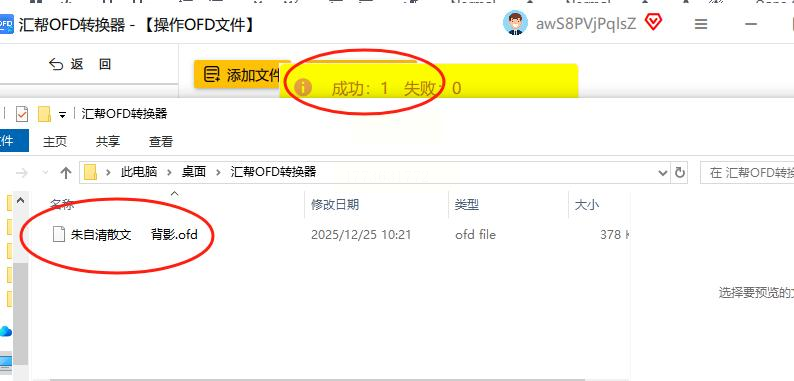
所有设置完成后,点击界面右下角或顶部的“开始转换”按钮。此时软件会显示转换进度条,你可以看到每一页的处理状态。
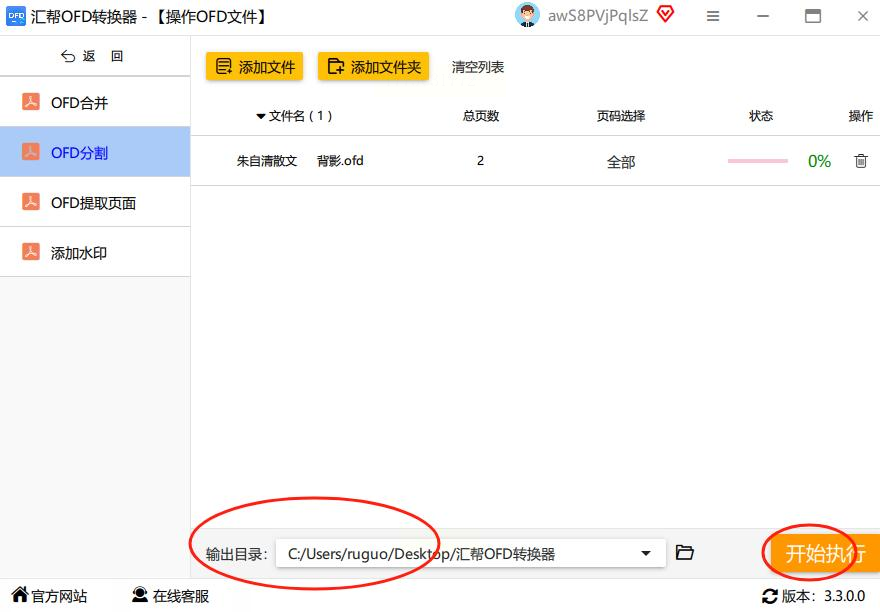
转换完成后,软件会弹出提示窗口告诉你成功信息。这时你可以直接打开刚才设置的输出文件夹,检查拆分后的单页OFD文件是否正确,确认无误后就可以将这些文件用于后续工作或学习了。
方法二:使用OFD Viewer Plus(轻量免费工具)
详细步骤
1. 安装与界面熟悉
首先从OFD Viewer Plus的官方网站下载安装包。安装过程非常简单,按照提示点击“下一步”即可完成。打开软件后,界面类似常见的PDF阅读器,左侧是文件导航栏,右侧是阅读区域,中间可以看到当前文档的页面内容。顶部菜单栏包含“文件”、“编辑”、“视图”等常用选项。
2. 导入文件并进入提取模式
点击左上角“文件”菜单中的“打开”选项,找到需要拆分的OFD文件并打开。打开后,在顶部菜单栏选择“编辑”,然后在下拉菜单中找到“页面管理”或“提取页面”功能。这个功能可以帮助你精确地选择要提取的页面范围。
3. 选择需要提取的页面
在弹出的页面提取窗口中,你会看到所有页面的缩略图列表。这里可以通过以下方式选择页面:
- 点击单个页码进行选择
- 按住鼠标左键拖动选择连续页面
- 按住Ctrl键点击多个不连续页面
选中的页面会以高亮显示,方便确认。
4. 提取与保存设置
确认选择的页面范围后,点击“提取”按钮。软件会弹出一个保存对话框,让你选择保存路径和文件名。此时你可以选择是否保留原文件的格式,通常软件会默认保持OFD格式,确保页面布局不变。保存完成后,拆分后的OFD文件会自动出现在指定位置。
方法三:Python脚本批量自动化处理
详细步骤
1. 安装必要的Python库
首先确保你的电脑已安装Python环境。然后需要安装OFD处理库ofdrw,可以通过命令行执行`pip install ofdrw`来安装。此外,还需要导入os模块用于文件路径处理。
2. 编写分割函数
创建一个Python脚本文件,例如`split_ofd.py`。在脚本中定义一个分割函数:
```python
from ofdrw import OFDReader, OFDWriter
import os
def split_ofd(input_path, output_dir):
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 读取OFD文件
with OFDReader(input_path) as reader:
total_pages = len(reader.pages)
for i in range(total_pages):
# 创建新的OFD写入器
writer = OFDWriter()
writer.copy(reader) # 复制原文件的元数据和结构
writer.set_pages(i, i + 1) # 提取第i页(从0开始计数)
# 生成输出文件名
file_name = os.path.basename(input_path)
file_stem = os.path.splitext(file_name)[0]
output_path = os.path.join(output_dir, f"{file_stem}_page{i+1}.ofd")
writer.save(output_path)
print(f"文件已成功拆分为单页,保存在{output_dir}")
```
3. 执行脚本处理文件
在命令行中执行以下命令:
```bash
python split_ofd.py "C:\Users\用户名\Documents\原始文件.ofd" "C:\Users\用户名\Documents\OFD拆分结果"
```
这里需要将路径替换为实际的OFD文件路径和输出目录路径。执行后,脚本会自动遍历每一页,生成对应的单页OFD文件。对于批量处理多个文件,你还可以添加循环结构,遍历指定文件夹中的所有OFD文件。
拆分OFD页面看似是一个小技巧,实则在日常办公和学习中能发挥重要作用。无论是使用可视化工具快速处理,还是通过编程实现自动化,选择适合自己的方法都能有效提升工作效率。通过本文介绍的3种方法,你可以根据实际需求和技术背景选择最适合的解决方案。
在实践中,建议先从简单的工具开始尝试,逐步探索更高级的功能,比如Python脚本自动化处理。随着熟练度的提升,你甚至可以将这些方法融入到自己的工作流中,实现文档处理的自动化和智能化,让技术真正成为提升效率的利器。
