

最近好多同事吐槽,每次要整理一堆PDF文件的名字,手动一个个复制粘贴,眼睛都快瞎了还容易错。我懂这种痛苦!上周帮新来的实习生处理100多个产品手册,她用了3小时才搞定,我用这个方法20分钟就导出了Excel表格。今天必须把这3个超实用的技能拆解给你们,再配上Excel的小技巧,保准你看完就能上手,再也不用跟PDF文件名较劲了!

一、【汇帮文件名提取器】保姆级操作:3步就能批量提取
先夸夸这个软件:界面像聊天软件一样简单,连我这种电脑小白第一次用都没卡壳。而且完全免费,不用安装乱七八糟的插件,处理1000个文件都不会卡(亲测!)。具体操作分三步,每步都给你标红重点!
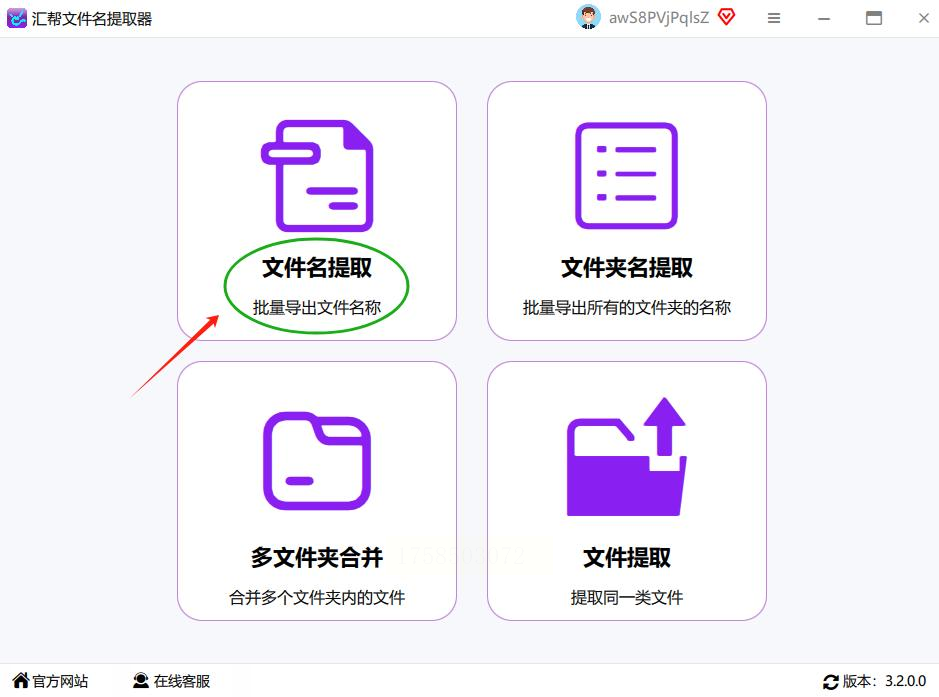
步骤1:文件“上车”超简单,支持文件夹批量导入
打开软件后,你会看到界面上有个“添加文件”和“添加目录”的按钮,新手先点“添加目录”更方便(如果你所有PDF都在一个文件夹里的话)。点击后会弹出文件选择窗口,找到你放PDF的文件夹,直接选中整个文件夹就行!
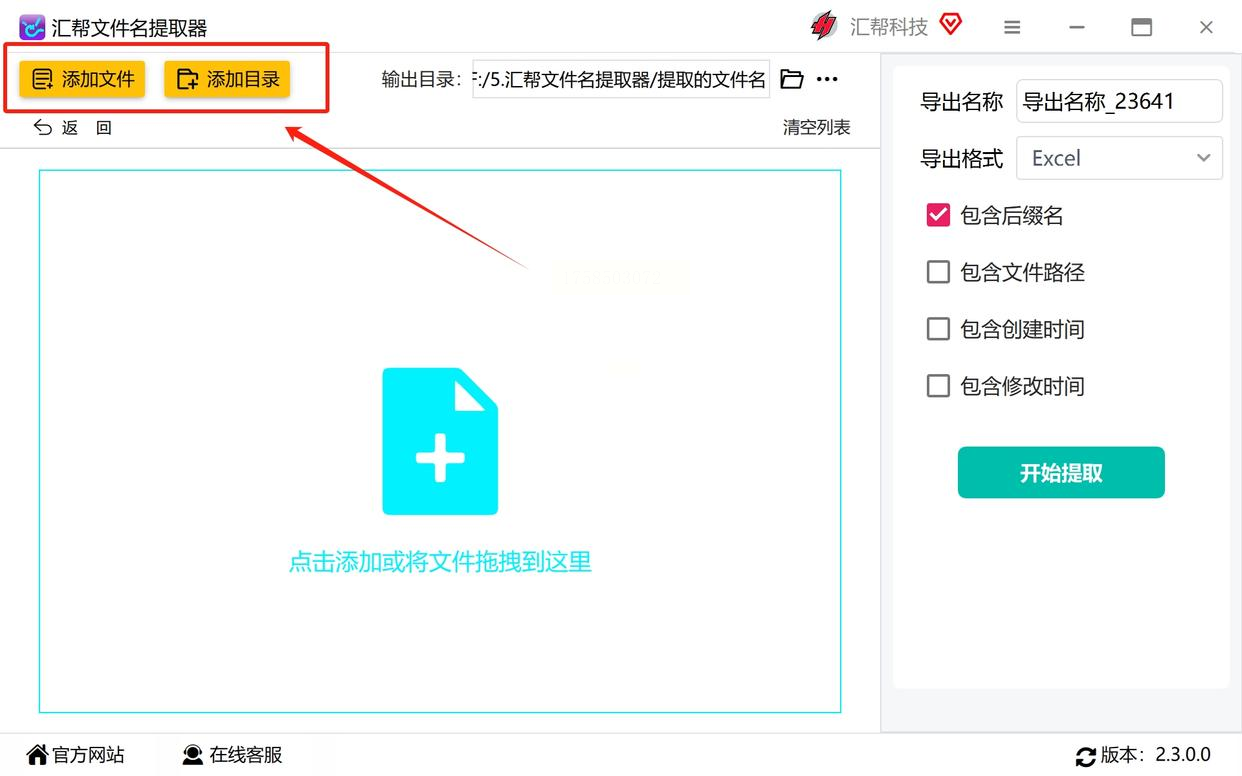
> ✨ 小技巧:要是PDF分布在多个文件夹,就一个个点“添加文件”也行,软件不会限制数量,你可以放心拖进来几百个。
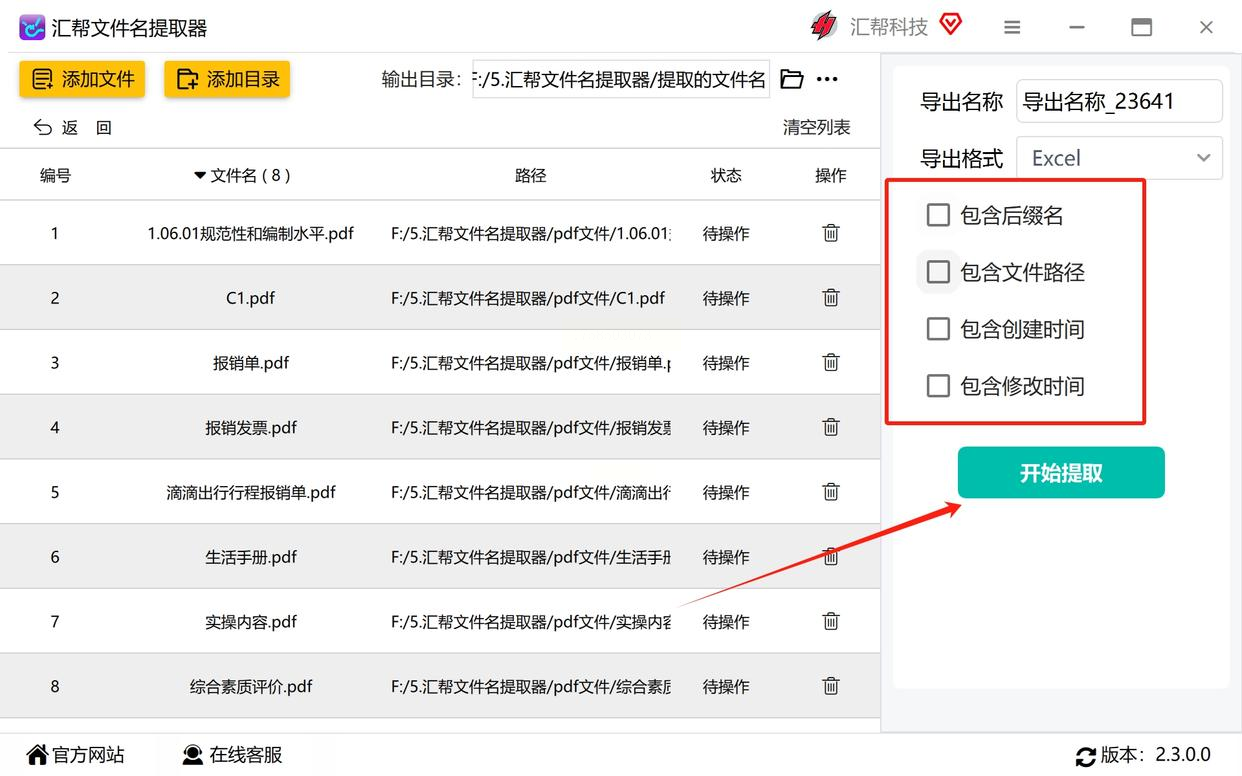
步骤2:设置提取“小零件”,想抓啥就抓啥
导入文件后,下面会出现几个选项框,这里是最关键的!比如你只想提取文件名(不带路径和大小),就直接勾选“文件名”;如果还要知道每个文件多大、创建时间,也可以都选上。我建议新手先只选“文件名”,后续熟悉了再加其他信息。
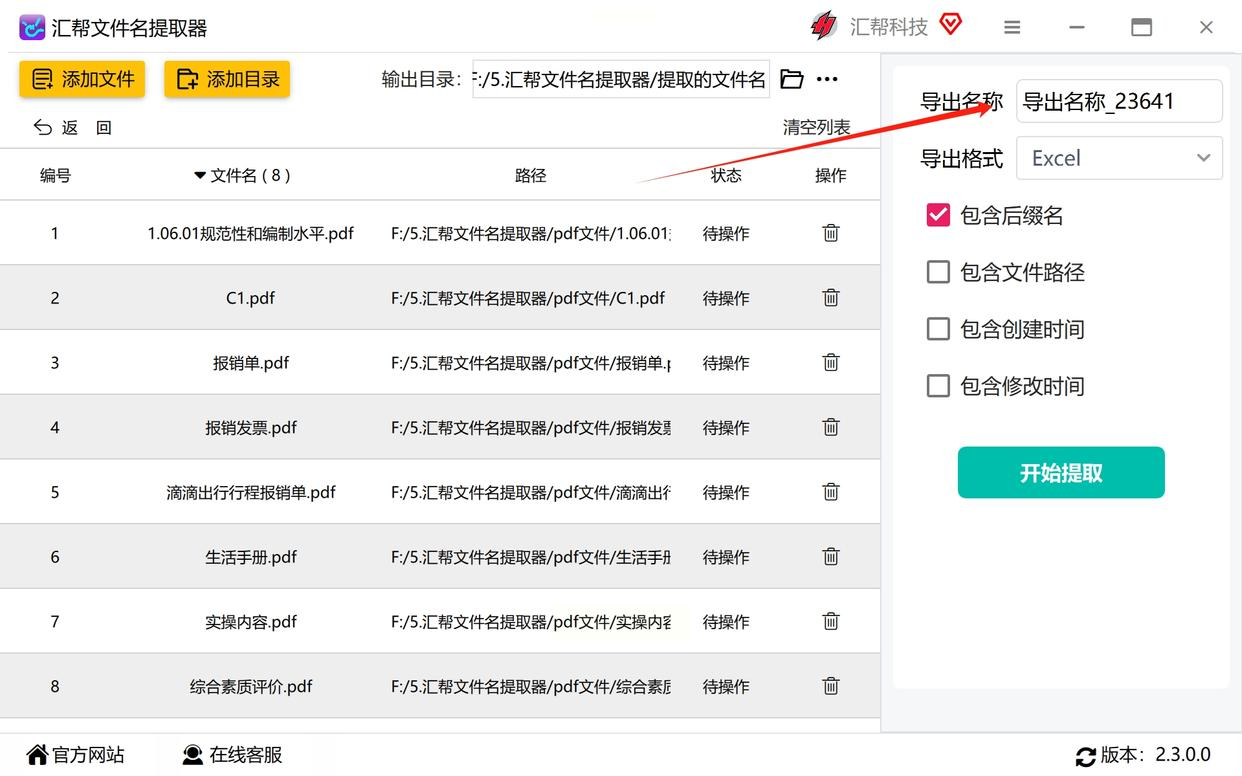
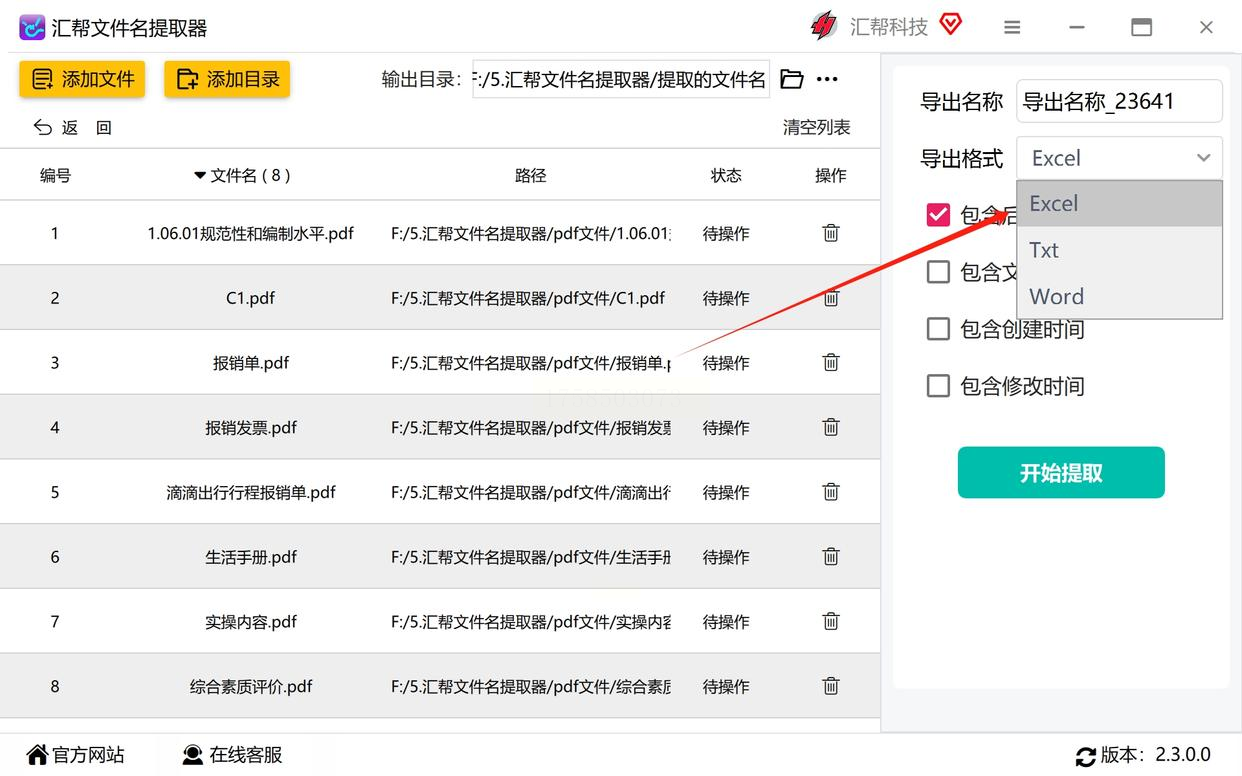
> 💡 重点:导出格式要选Excel!后面还要用Excel分析,选CSV或者TXT的话还得再转换,多一步麻烦。
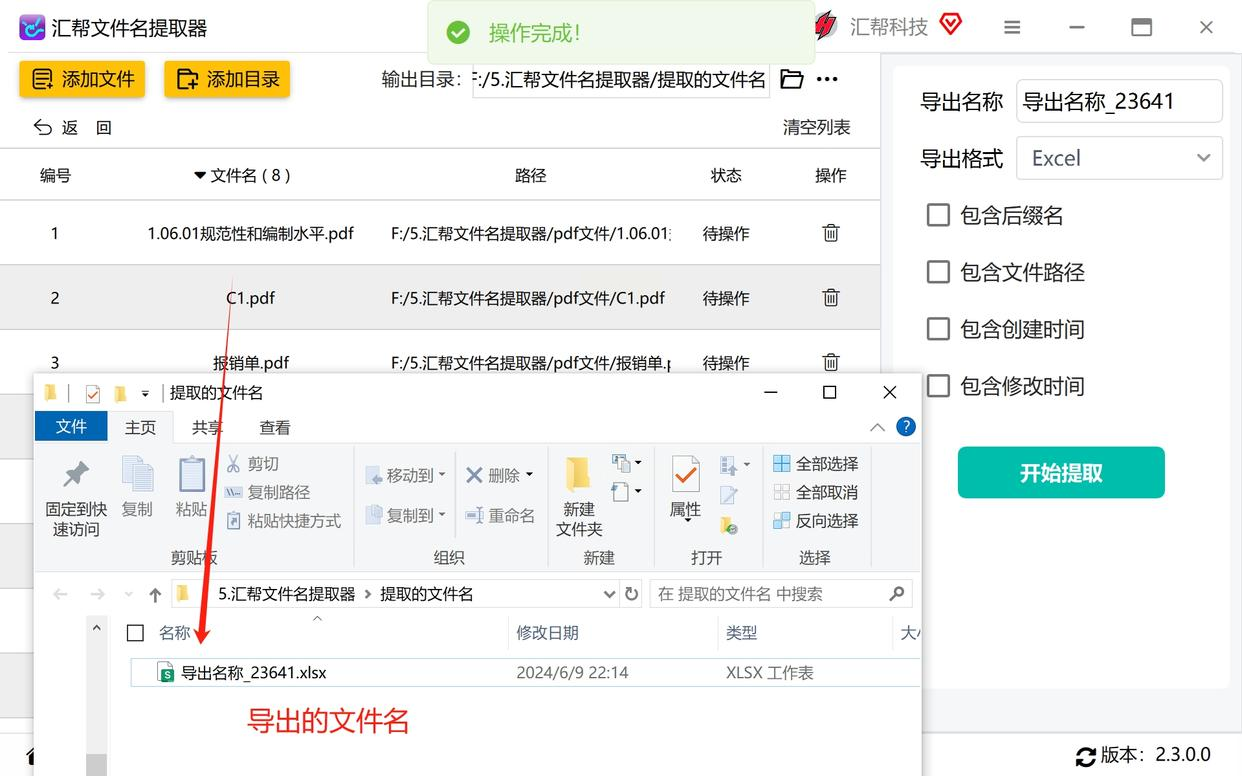
步骤3:一键“发车”,等3秒就搞定
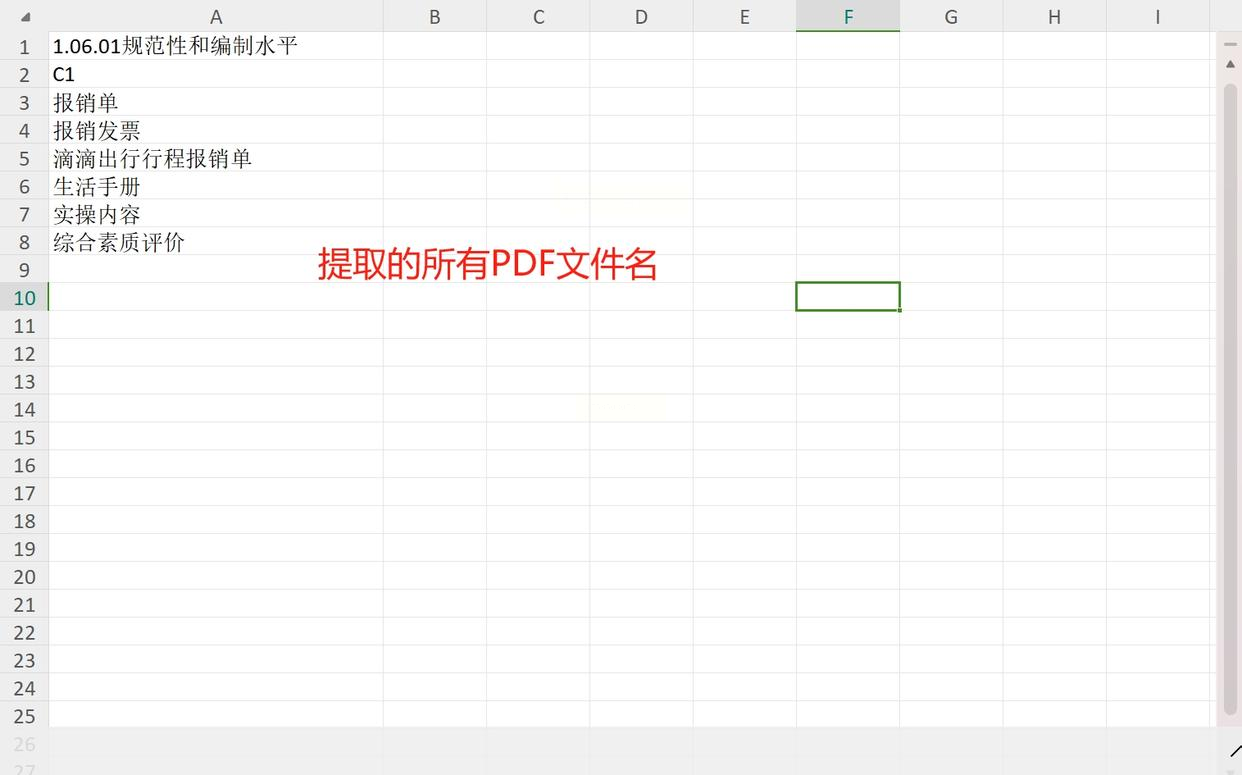
最后点“开始提取”,软件会自动扫描所有PDF,进度条走完后会弹出提示“提取完成”。这时候去你设置的输出文件夹里找,就能看到一个Excel文件,里面整整齐齐列着所有PDF的名字,连扩展名都没多余!
> 😎 实测效果:我上次处理200个PDF,导出的Excel连换行符都自动调好,直接复制就能用,比手动敲快10倍!
二、Excel快捷导入法:适合要“二次加工”的表格党
除了软件,Excel自带的小功能也能搞定!但这个方法适合需要给文件名加前缀、统计数量的情况,比如给所有文件加个“项目资料-”的开头。步骤如下:
步骤1:用命令提示符“生成文件清单”
1. 按 `Win+R` 弹出运行窗口,输入 `cmd` 按回车,打开黑色的命令行窗口。
2. 输入 `cd` 后面加空格,然后把你的PDF文件夹拖到窗口里(会自动显示路径),比如 `cd D:\工作文件\产品手册`,按回车切换到目标文件夹。
3. 敲命令 `dir /b *.pdf > filenames.txt`,按回车!这时候你会发现文件夹里多了个 `filenames.txt` 文件,里面全是PDF的名字,一个一行!
步骤2:把TXT直接“拽”进Excel
1. 打开Excel,点菜单栏的“数据”选项卡,找到“自文本/CSV”(Excel版本不同可能叫“从文本文件”)。
2. 选中刚才生成的 `filenames.txt` 文件,点“导入”。这时候会弹出“文本导入向导”,默认选“分隔符号”,下一步直接点“完成”就行。
3. 导入后Excel里会自动生成一列,每个PDF名字都在单独一行,这时候你就可以用“查找替换”或者“数据分列”功能加工名字了。
步骤3:加工文件名,想改啥就改啥
比如要给所有文件名加“2023Q4-”的前缀,直接选中第一列,按 `Ctrl+H` 调出替换窗口,在“查找内容”里留空,“替换为”里输入 `2023Q4-` 按回车就行!Excel处理这种批量操作,简直比手动改快100倍!
三、Python脚本法:程序员同事专属,代码党狂喜!
如果你是程序员或者喜欢折腾代码的,Python脚本是最快的“黑科技”!不用等软件加载,几行代码就能把所有PDF名字扒下来,适合处理上万份文件的大佬。不过这方法需要装Python,适合有基础的同事试试:
步骤1:安装Python和必要库
打开官网下载Python,安装时记得勾选“Add to PATH”。然后打开命令行,输入 `pip install os`(其实os是Python自带的,不用装,直接用就行)。
步骤2:复制代码改路径
把下面这段代码复制到文本编辑器,比如记事本:
```python
import os
def get_pdf_names(folder):
pdf_list = []
for filename in os.listdir(folder):
if filename.endswith('.pdf'):
pdf_list.append(filename)
return pdf_list
# 这里改成你的PDF文件夹路径!
pdf_folder = "D:\\工作文件\\全部PDF"
result = get_pdf_names(pdf_folder)
# 把结果写入Excel(需要安装pandas和openpyxl库)
import pandas as pd
df = pd.DataFrame(result, columns=['文件名'])
df.to_excel('pdf_names.xlsx', index=False)
print("提取完成!文件已保存为pdf_names.xlsx")
```
> 🚨 警告:路径要注意用双反斜杠,比如 `D:\\文件夹\\子文件夹`,别用单斜杠,不然会报错!
步骤3:运行脚本,秒出Excel
保存成 `pdf_extractor.py`,然后在命令行输入 `python pdf_extractor.py`,等一下就能在同目录看到生成的Excel文件,里面全是PDF名字!
四、总结:别再手动复制粘贴了!工具用对效率翻倍
现在你知道了,处理PDF文件名根本不用逐个打开复制!汇帮文件名提取器这种“懒人神器”,加上Excel的基础操作,就能轻松解决。记住三个核心步骤:软件一键导入导出、Excel快速加工、Python代码自动化,根据自己的情况选方法就行。
最后送大家一句话:与其花1小时手动扒名字,不如花5分钟学个工具。下次再遇到这种问题,直接打开汇帮软件,点两下鼠标就搞定了!
现在就去试试吧,处理完记得回来给我点个赞哦~有任何操作问题,评论区问我,包教包会!
