

为什么我们需要批量去掉外层文件夹?
在日常工作和生活中,我们几乎每天都要与各种电子文件打交道。无论是整理工作文档、归类家庭照片,还是管理下载的资源文件,文件夹都是我们组织信息的基本单元。然而,随着时间推移和文件数量不断增加,我们常常会遇到一个普遍存在的问题:文件夹嵌套过深,结构过于复杂。
想象一下这样的场景:你从网上下载了一个资源包,解压后发现里面包含了上百个文件夹,每个文件夹里可能只有一两个文件;或者你从同事那里接收了一个项目资料,里面的文件被层层包裹在“年份→月份→日期→项目名称”的多级目录中;又或者你多年来积累的照片,按照“设备→年份→事件→精选”的层级存放,现在想要快速浏览所有照片却需要不断点击进入层层文件夹。这些情况不仅降低了文件检索效率,还占用了额外的存储空间,更给文件备份、共享和迁移带来了诸多不便。
因此,学会批量去掉外层文件夹,将嵌套结构“扁平化”,成为了一项实用的文件管理技能。这项技能不仅能帮助我们简化文件结构,提高工作效率,还能优化存储空间使用,便于文件共享和备份。下面,我将详细介绍五种实现这一目标的方法,每种方法都有其适用场景和操作特点,您可以根据自己的具体需求和技能水平选择合适的方法。
怎样批量移除外层文件夹,直接获取所有子文件到同一目录?

第一种方法:使用“汇帮文件名提取器”软件一键去除外层文件夹,把文件合并到一个目录中
第一步:获取并安装软件
1. 下载完成后,按照安装向导提示完成软件安装
2. 启动软件,熟悉界面布局和主要功能区域
第二步:选择功能模式
1. 在软件主界面中,您会看到多个功能选项
2. 找到并点击“文件夹合并”功能按钮,进入该功能的工作界面
3. 花一点时间了解界面各个部分的作用:左侧通常是文件夹列表区域,中间是预览区域,右侧是设置选项
第三步:添加需要处理的文件夹
1. 点击“添加文件夹”按钮,会弹出文件夹选择对话框
2. 在对话框中选择最外层的文件夹(即包含所有需要处理子文件夹的那个文件夹)
3. 您也可以使用拖拽方式:直接打开文件资源管理器,将目标文件夹拖放到软件界面中
4. 添加成功后,您会在列表中看到已添加的文件夹及其路径信息
5. 如果需要处理多个独立的顶层文件夹,可以重复此步骤添加多个

第四步:设置输出目录
1. 找到“输出目录”或“目标文件夹”设置项
2. 点击旁边的“浏览”按钮,选择一个用于存放提取后文件的位置
3. 建议选择一个空文件夹或新建一个文件夹,避免与现有文件混淆
4. 记下这个路径,方便后续查找处理结果
第五步:配置合并选项
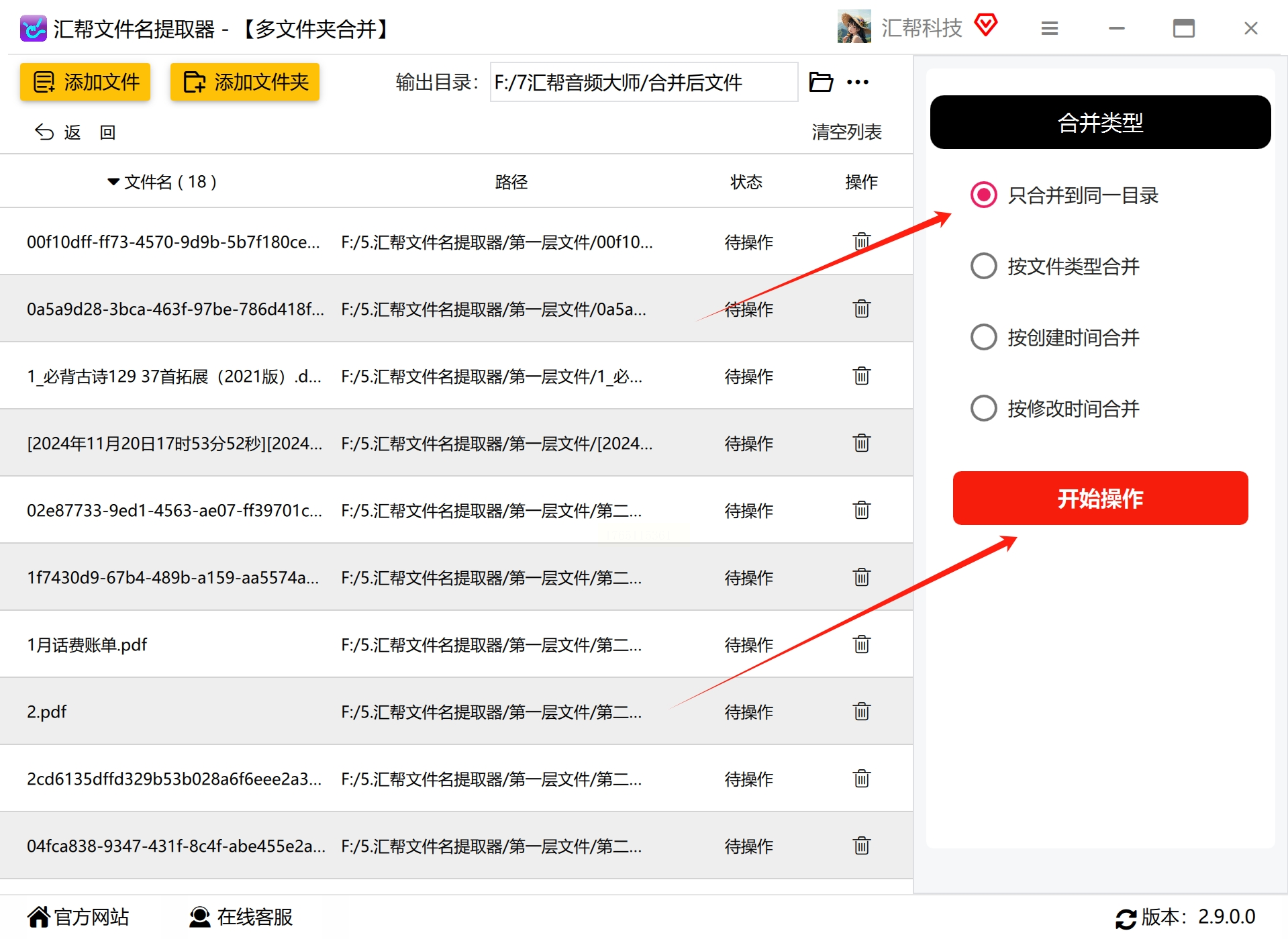
1. 在右侧设置区域找到“合并类型”选项
2. 从下拉菜单中选择“只合并到同一目录”选项
3. 了解其他可用的合并方式:
- “按文件类型合并”:将相同扩展名的文件放在一起
- “按创建时间合并”:根据文件创建日期组织文件
- “按修改时间合并”:根据最后修改时间组织文件
4. 根据您的需求,可以探索这些选项,但本次操作选择“只合并到同一目录”
第六步:执行提取操作
1. 检查所有设置是否正确
2. 确认已选择的文件夹和输出目录符合预期
3. 点击“开始操作”或“执行”按钮启动处理过程
4. 观察进度条或状态提示,了解处理进度
5. 处理时间取决于文件数量和大小,请耐心等待
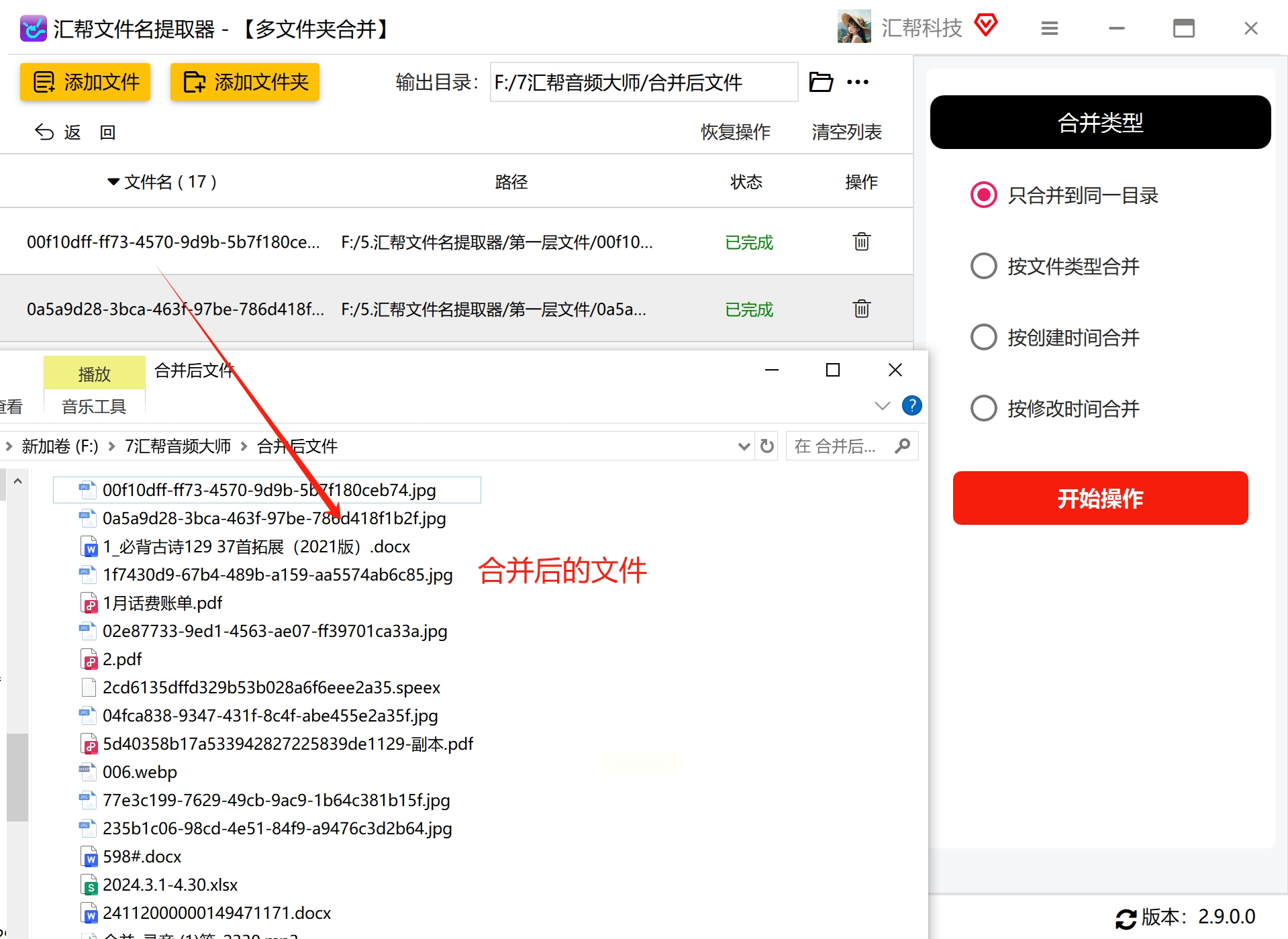
第七步:验证处理结果
1. 操作完成后,软件会显示完成提示
2. 按照之前设置的输出目录,在文件资源管理器中打开该文件夹
3. 检查所有文件是否已从原子文件夹中提取出来
4. 确认文件数量是否与预期一致
5. 随机打开几个文件,确保文件没有损坏

第二种方法:使用Python脚本自动化处理
当您需要处理的文件夹数量众多,且具备一定的编程基础或愿意学习简单脚本操作时,使用Python脚本是一个高效的选择。这种方法特别适合需要定期执行类似任务的情况,因为脚本可以保存并重复使用。
操作步骤
第一步:准备工作环境
1. 确保您的计算机上已安装Python。如果没有安装,可以从Python官网下载并安装最新版本
2. 创建一个专门用于存放脚本的工作目录,避免与其他文件混淆
3. 备份您要处理的文件夹,以防操作失误导致数据丢失
第二步:编写脚本内容
1. 打开文本编辑器(如记事本、Notepad++或VS Code)
2. 输入以下代码内容:
```python
import os
import shutil
def flatten_folders(target_path):
"""
将目标路径下所有子文件夹中的文件移动到目标路径,
然后删除空的子文件夹
"""
# 检查目标路径是否存在
if not os.path.exists(target_path):
print(f"错误:路径'{target_path}'不存在")
return
# 获取目标路径下的所有项目
items = os.listdir(target_path)
# 筛选出其中的文件夹
folders = [item for item in items
if os.path.isdir(os.path.join(target_path, item))]
print(f"找到 {len(folders)} 个文件夹需要处理")
# 遍历每个文件夹
for folder in folders:
folder_path = os.path.join(target_path, folder)
try:
# 获取文件夹中的所有内容
contents = os.listdir(folder_path)
# 移动每个文件到目标路径
for item in contents:
src = os.path.join(folder_path, item)
dst = os.path.join(target_path, item)
# 处理目标文件已存在的情况
if os.path.exists(dst):
base_name, extension = os.path.splitext(item)
counter = 1
new_item_name = f"{base_name}_{counter}{extension}"
dst = os.path.join(target_path, new_item_name)
while os.path.exists(dst):
counter += 1
new_item_name = f"{base_name}_{counter}{extension}"
dst = os.path.join(target_path, new_item_name)
shutil.move(src, dst)
print(f"已移动: {item}")
# 检查文件夹是否已空,如果是则删除
if not os.listdir(folder_path):
os.rmdir(folder_path)
print(f"已删除空文件夹: {folder}")
else:
print(f"注意:文件夹'{folder}'非空,未删除")
except Exception as e:
print(f"处理文件夹'{folder}'时出错: {str(e)}")
print("处理完成")
if __name__ == "__main__":
# 在此处设置要处理的目标文件夹路径
target_directory = "请输入您的目标文件夹完整路径"
flatten_folders(target_directory)
```
第三步:配置脚本参数
1. 将代码中的`"请输入您的目标文件夹完整路径"`替换为您实际要处理的文件夹路径
2. 例如,如果您的文件夹在D盘的“待整理文件”中,可以替换为:`"D:\\待整理文件"`(注意使用双反斜杠)
第四步:保存并运行脚本
1. 将文件保存为`flatten_folders.py`
2. 打开命令提示符或终端
3. 使用`cd`命令切换到脚本所在目录
4. 输入`python flatten_folders.py`并按回车执行
第五步:检查处理结果
1. 脚本运行完成后,查看目标文件夹
2. 确认所有文件已从子文件夹中移出
3. 检查是否有文件因重名而被添加了数字后缀
4. 确认空的子文件夹已被删除
注意事项
- 首次使用前,一定要在测试文件夹上运行脚本,确保理解其工作原理
- 如果文件夹中包含系统文件或隐藏文件,脚本可能无法移动它们
- 对于有特殊权限要求的文件,可能需要以管理员身份运行脚本
- 建议在处理前关闭所有可能访问这些文件的程序
这两个方法都能帮我们实现移除外层文件夹的功能。
