

在信息高度密集的现代办公环境中,PowerPoint演示文稿已成为知识传递、项目汇报与教育培训的核心载体。然而,随着工作年限的增长与项目数量的积累,大量PPT文件往往分散存储于不同的文件夹层级中,形成了杂乱无章的“数字孤岛”。这种分散存储模式不仅增加了文件检索的时间成本,更对资料的整体梳理、内容复用及价值挖掘造成显著阻碍。无论是学术研究者需要对历年研讨会PPT进行主题分析,还是企业管理者希望整合各部门的项目汇报材料,亦或是教师需要汇总不同学期的教学课件,高效地从多级目录中批量提取PPT文件已成为提升工作效率的关键环节。传统的手动查找方式不仅耗时费力,且极易因人为疏忽导致文件遗漏。因此,掌握智能化的文件提取技术,选择适合自身技术背景与需求的解决方案,对实现办公自动化、释放人力资源具有重要的实践意义。本文将深入探讨多种PPT文件提取方案,重点关注操作便捷性、功能适应性及技术门槛的平衡,帮助读者构建科学高效的文件管理策略。

一、汇帮文件名提取器——面向非技术用户的图形化解决方案
对于追求操作简便、无需编程基础的用户群体,专业文件管理工具提供了更为直观的操作体验。汇帮文件名提取器通过精心设计的图形界面,将复杂的文件检索过程简化为几个点击操作。
详细操作指南
步骤一:启动软件并配置扫描范围
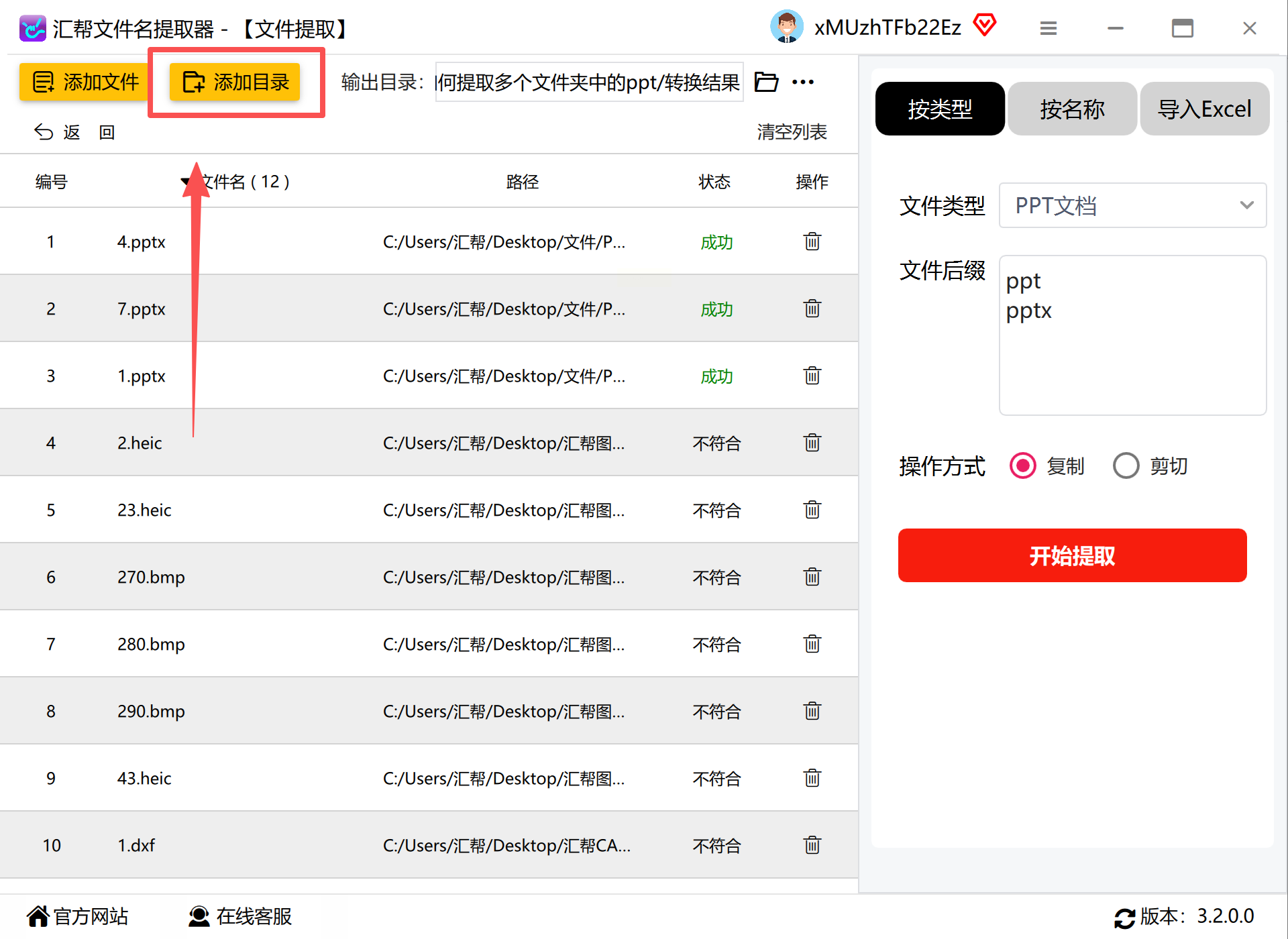
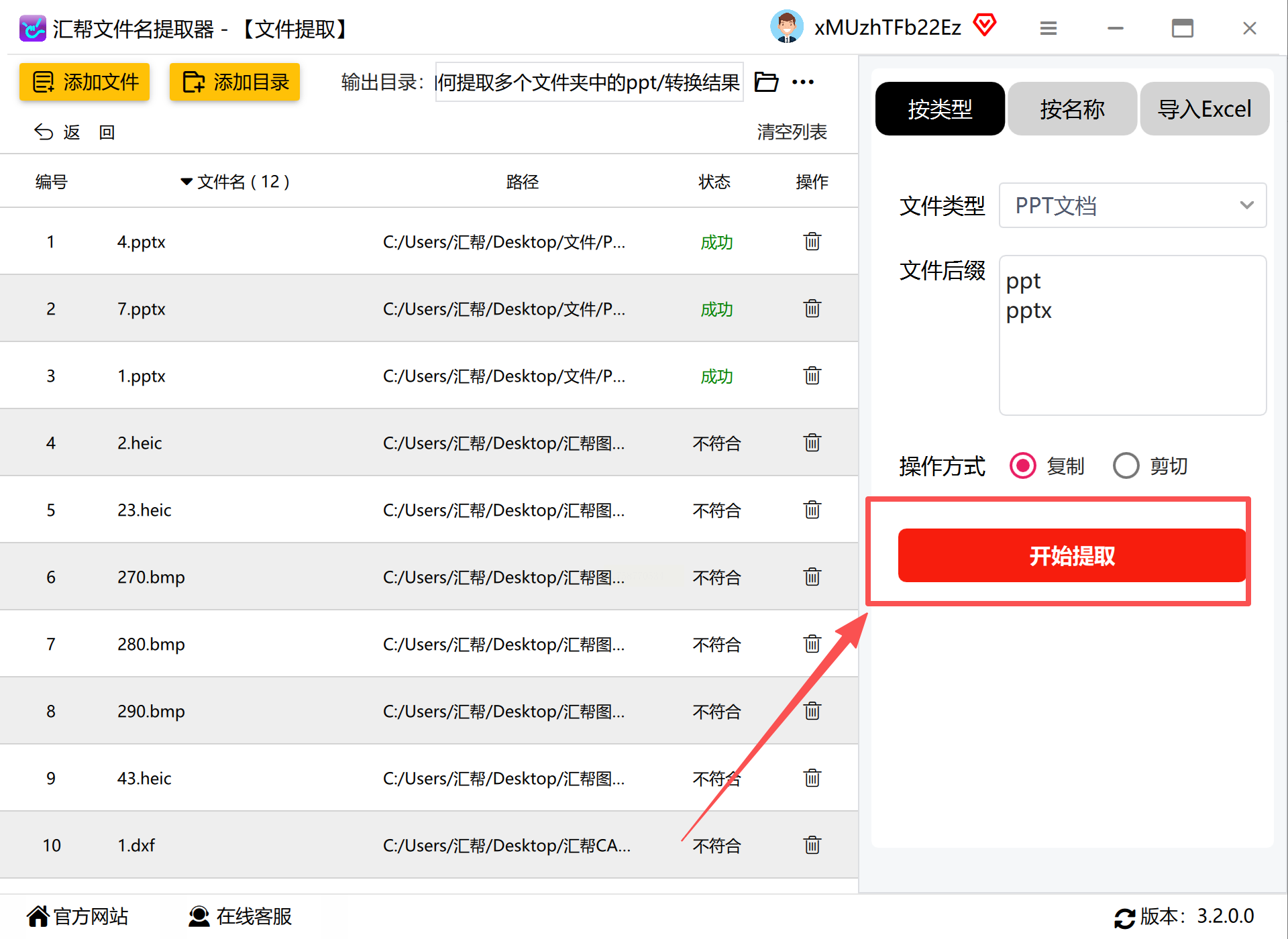
运行程序后,在主界面选择“文件提取”模式。
点击“添加文件夹”按钮,依次选择需要扫描的顶层文件夹。软件支持同时添加多个不相邻的目录,并自动记忆最近使用路径。
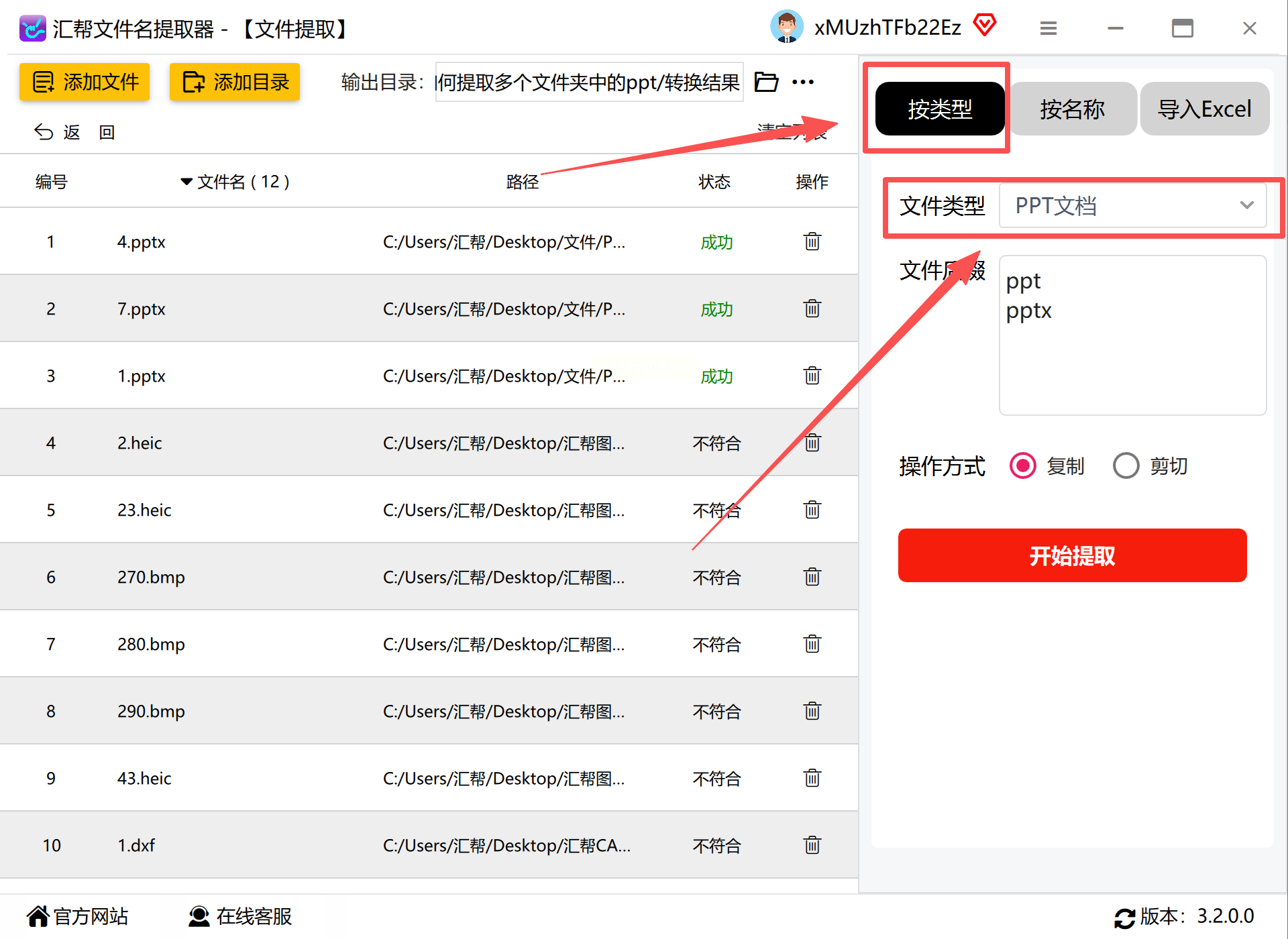
步骤二:设定文件类型过滤条件
在“文件类型”筛选区域,勾选“PPT演示文稿”选项(通常包含.ppt和.pptx扩展名)。高级设置中可进一步按文件大小、修改日期范围进行筛选,例如仅提取最近三个月内超过1MB的演示文稿。
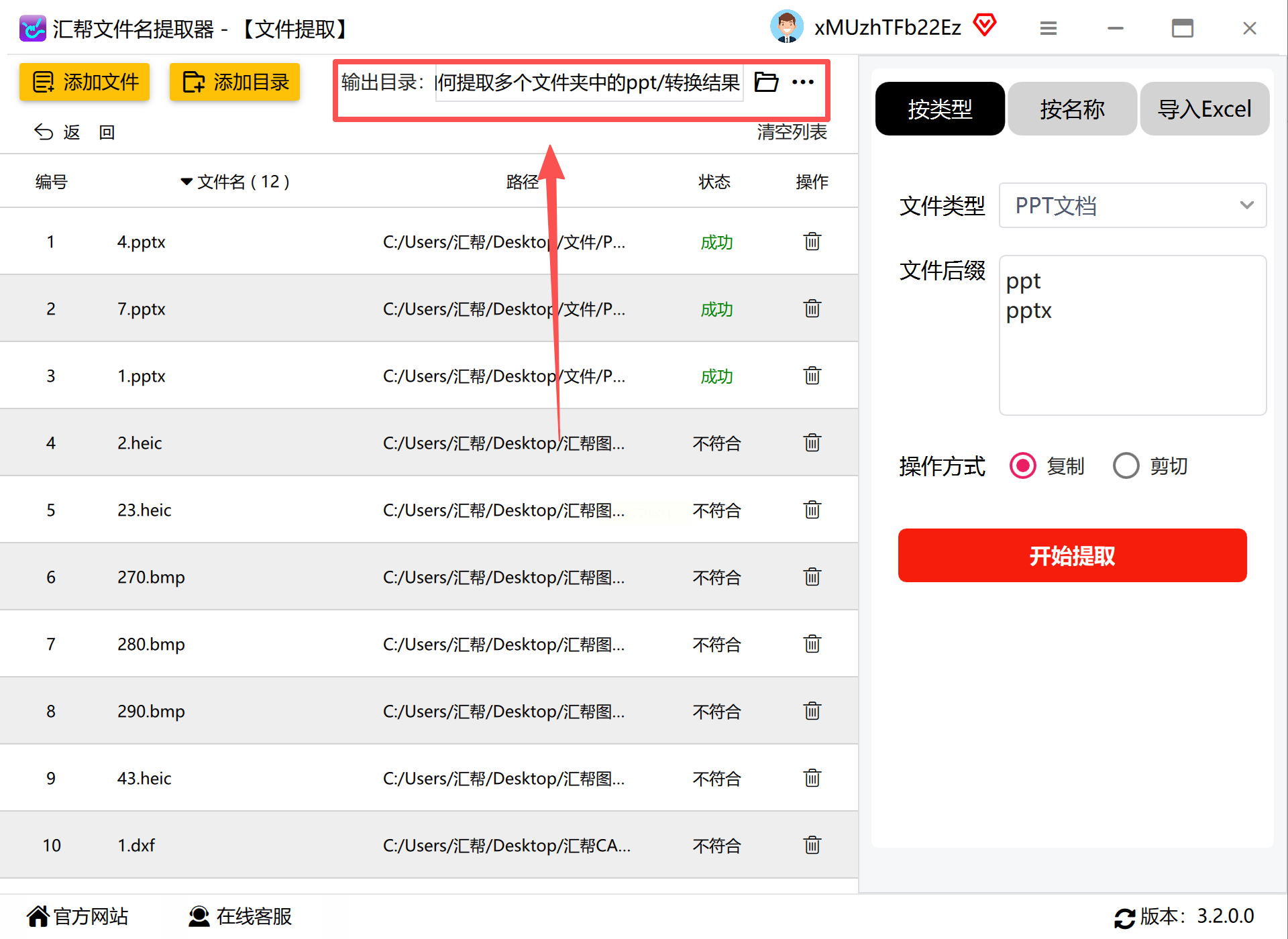
步骤三:指定输出路径与命名规则
通过“浏览”按钮选择文件提取后的存储位置。建议新建专用文件夹避免与原有文件混淆。在“文件处理”选项卡中,可设置遇到同名文件时的处理策略(自动重命名、跳过或覆盖),同时支持按原始目录结构创建子文件夹。
步骤四:执行提取与结果验证
点击“开始提取”按钮后,界面将实时显示扫描进度、已发现文件数量及当前处理状态。操作完成后,软件会生成详细报告,包括成功提取文件列表、跳过文件原因及可能存在的错误信息。用户可通过内置的预览功能快速验证重点文件内容。
二、Python自动化脚本——面向技术开发者的灵活解决方案
对于具备编程基础或希望将文件提取功能集成到现有工作流的技术人员而言,Python脚本提供了高度自由化的实现路径。该方案通过编写简洁的代码逻辑,能够实现跨平台、可定制的文件批量操作。
环境配置与基础操作流程
步骤一:安装Python运行环境
访问Python官方网站下载最新稳定版本,安装过程中务必勾选“Add Python to PATH”选项,以确保系统能够识别Python命令。完成安装后,可在命令行界面输入`python --version`验证安装结果。
步骤二:编写核心提取脚本
新建文本文件并写入以下代码,将文件后缀名改为`.py`:
```python
import os
import shutil
def extract_ppts(source_root, target_dir):
# 自动创建目标文件夹(若不存在)
os.makedirs(target_dir, exist_ok=True)
file_count = 0
# 遍历源目录及其所有子目录
for current_path, subdirs, filenames in os.walk(source_root):
for filename in filenames:
# 识别PPT格式文件(兼容新旧版本)
if filename.lower().endswith(('.ppt', '.pptx')):
source_file = os.path.join(current_path, filename)
target_file = os.path.join(target_dir, filename)
# 处理文件名重复情况(自动添加序号)
counter = 1
while os.path.exists(target_file):
name_parts = os.path.splitext(filename)
target_file = os.path.join(target_dir, f"{name_parts[0]}_{counter}{name_parts[1]}")
counter += 1
shutil.copy2(source_file, target_file) # 保留文件元数据
print(f"成功提取:{source_file}")
file_count += 1
print(f"操作完成!共提取 {file_count} 个PPT文件")
# 设置路径参数(需根据实际情况修改)
source_folder = "D:/项目资料" # 原始文件存储路径
destination_folder = "C:/集中管理/PPT合集" # 目标存储路径
extract_ppts(source_folder, destination_folder)
```
步骤三:执行提取任务
通过命令行导航至脚本所在目录,输入`python 脚本名称.py`运行程序。系统将自动遍历指定目录下的所有子文件夹,并将发现的PPT文件复制到目标位置,同时在界面显示实时操作日志。
进阶功能扩展
对于超大规模文件提取需求,可通过多线程技术提升效率:
```python
from concurrent.futures import ThreadPoolExecutor
import threading
lock = threading.Lock()
def parallel_copy(file_info):
source, target = file_info
with lock:
if not os.path.exists(target):
shutil.copy2(source, target)
print(f"线程{threading.current_thread().name}处理:{source}")
file_pairs = []
for root, _, files in os.walk(source_folder):
for file in files:
if file.lower().endswith(('.ppt', '.pptx')):
src = os.path.join(root, file)
dst = os.path.join(destination_folder, file)
file_pairs.append((src, dst))
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(parallel_copy, file_pairs)
```

三、Windows PowerShell脚本——系统管理员的专属利器
对于Windows平台的技术支持人员,系统内置的PowerShell提供了无需额外依赖的轻量级解决方案。该方案特别适合在域环境或受控办公场景中部署。
操作流程详解
以管理员身份启动Windows PowerShell,执行以下命令序列:
```powershell
# 设置路径参数
$sourcePath = "E:\部门文档"
$backupPath = "F:\归档PPT\$(Get-Date -Format 'yyyyMMdd')"
# 创建按日期命名的目标文件夹
New-Item -ItemType Directory -Path $backupPath -Force
# 执行递归提取(包含空目录处理)
Get-ChildItem -Path $sourcePath -Recurse -Include "*.ppt", "*.pptx" -ErrorAction SilentlyContinue |
ForEach-Object {
try {
$newName = "{0}_{1}{2}" -f $_.BaseName, [guid]::NewGuid().ToString("N").Substring(0,8), $_.Extension
Copy-Item -Path $_.FullName -Destination (Join-Path $backupPath $newName) -PassThru |
Add-Member -NotePropertyName "OriginalPath" -NotePropertyValue $_.DirectoryName -PassThru
}
catch {
Write-Warning "文件 $($_.Name) 提取失败: $($_.Exception.Message)"
}
} |
Export-Csv -Path "$backupPath\提取日志.csv" -NoTypeInformation -Encoding UTF8
Write-Host "操作完成!结果保存在 $backupPath" -ForegroundColor Green
```
在数字化办公深入发展的今天,文件管理已从简单的存储操作演变为影响组织效能的关键因素。通过本文介绍的多种PPT提取方案,我们不仅解决了具体的技术问题,更揭示了现代化文件管理的核心逻辑——将重复性劳动转化为自动化流程,让人力资源聚焦于更具创造性的工作。值得注意的是,技术工具的选择只是效率提升的一个环节,真正可持续的办公优化还需要配套的管理策略:建立清晰的文件分类标准、制定团队协作规范、定期进行资料归档清理。当技术手段与管理智慧相结合时,散落在各处的PPT文件将不再是负担,而是能够随时调用的知识宝库,为个人与组织的持续发展提供坚实的信息支撑。未来,随着人工智能技术在文档处理领域的深入应用,我们有望看到更智能的文件内容识别、自动标签生成和语义检索功能,进一步降低信息管理的成本,让知识创造和价值挖掘变得更为高效便捷。
