

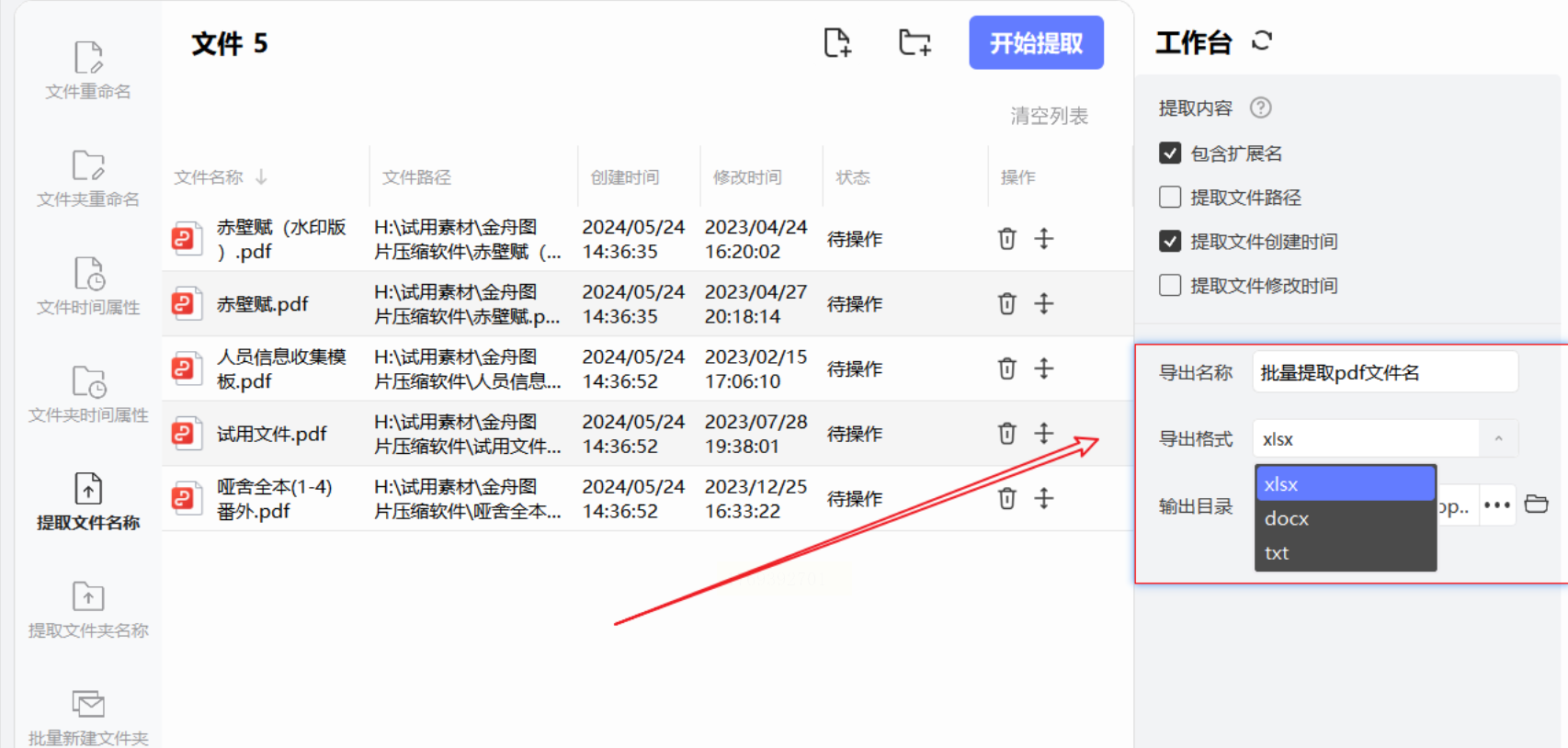
一、为什么要批量提取PDF文件名?
在日常工作中,我们经常会遇到需要处理大量PDF文件的场景:比如整理合同档案、分类教学课件、汇总项目文档等。如果手动逐个复制文件名,不仅需要花费大量时间,还容易出错。尤其是当文件数量达到几十甚至上百个时,这种低效的方式会严重影响工作进度。
典型使用场景:
- 文件归档:将合同、发票、项目资料等PDF按类型分类时,需要先明确每个文件的名称和版本
- 数据统计:给领导汇报PDF文档数量或版本时,用Excel表格呈现更直观
- 团队协作:与同事共享PDF资料时,提前整理文件名清单能避免对方反复询问文件内容
- 备份管理:给重要PDF文件做备份时,先提取文件名便于后续核对和检索
手动提取很浪费时间也容易出错。
怎么批量提取pdf命名?3个简单快速的文件名提取方法

方法1:使用界面话的工具“汇帮文件名提取器”帮我们批量提取PDF命名
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
1. 下载安装:
- 在官网搜索"汇帮文件名提取器"
2. 提取PDF文件名:
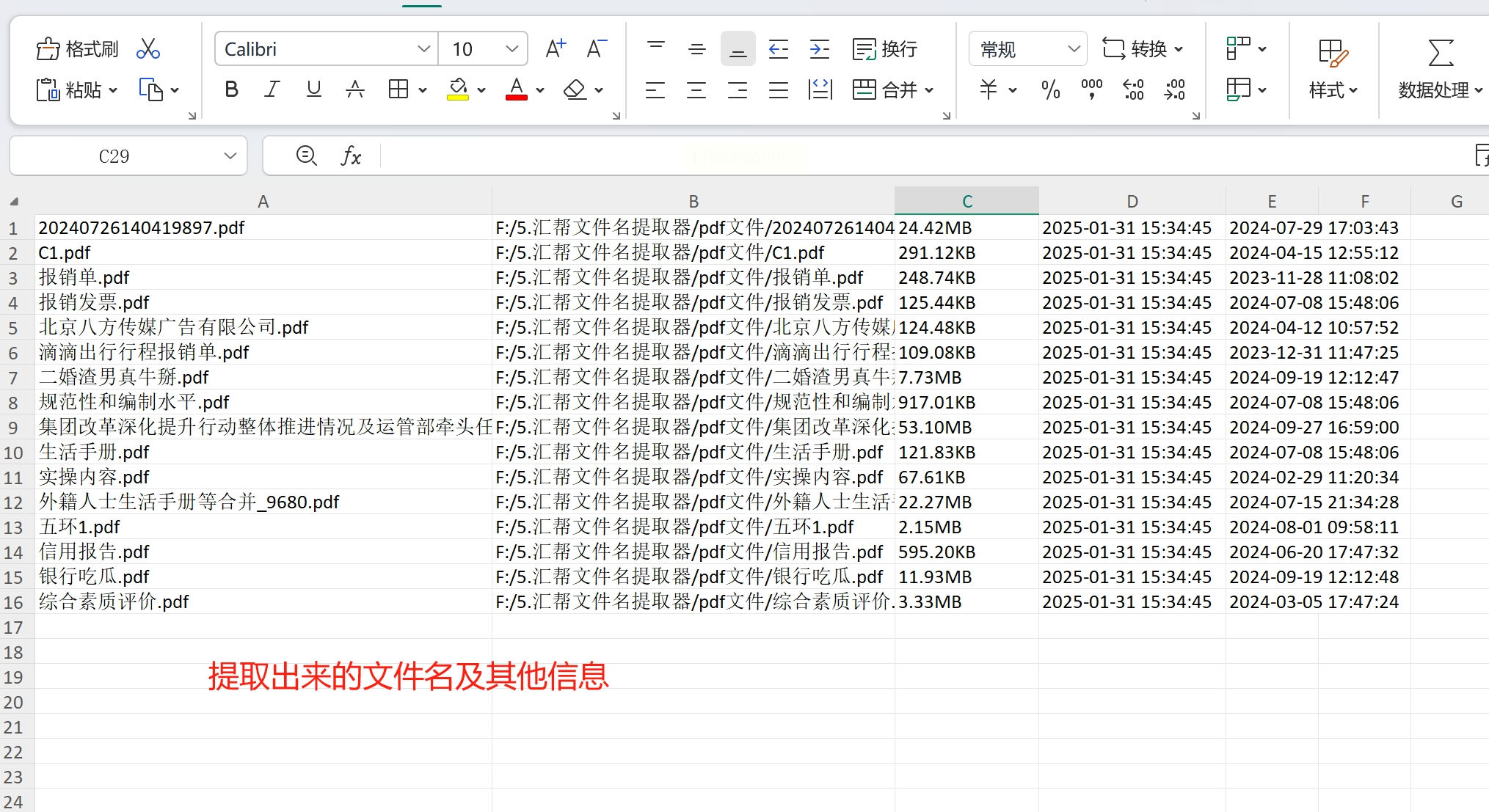
- 步骤1:启动软件,选择"批量提取文件名"功能
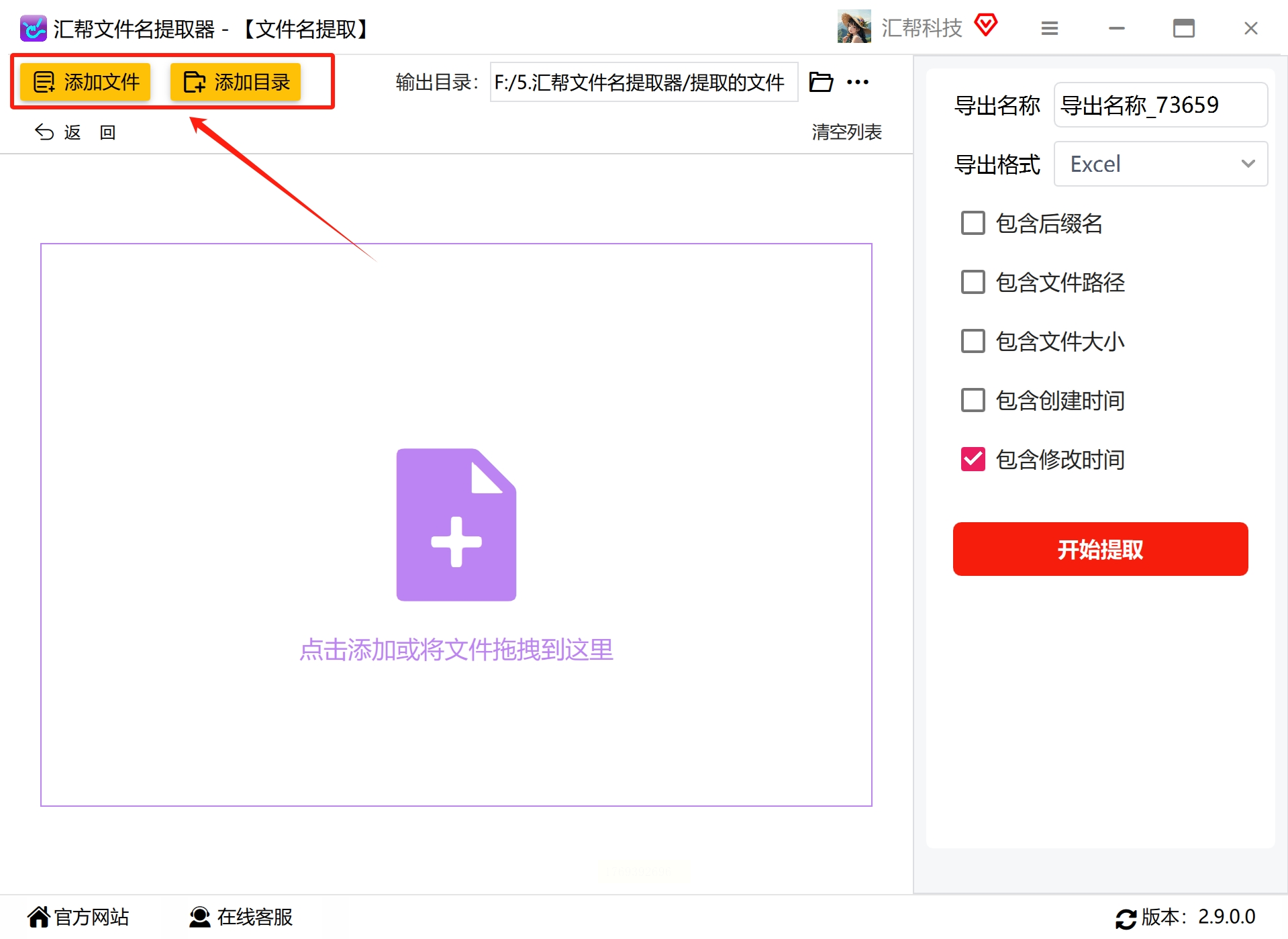
- 步骤2:点击"添加文件"或"添加文件夹",选择PDF文件所在目录
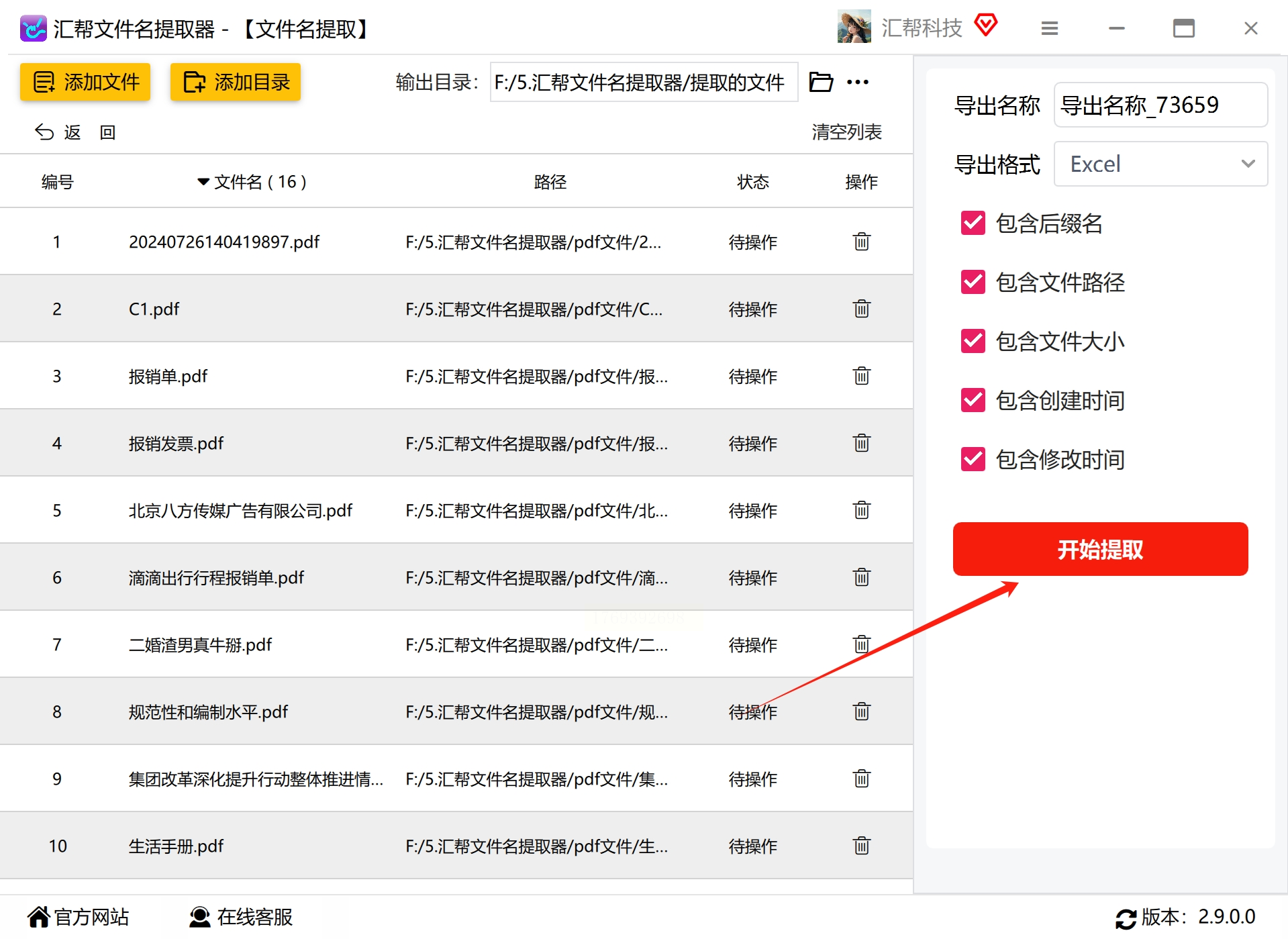
- 步骤3:设置导出格式为Excel(.xlsx)
- 步骤4:可选择提取内容(仅文件名/含路径/含修改日期等)
- 步骤5:点击"开始提取",等待进度条完成
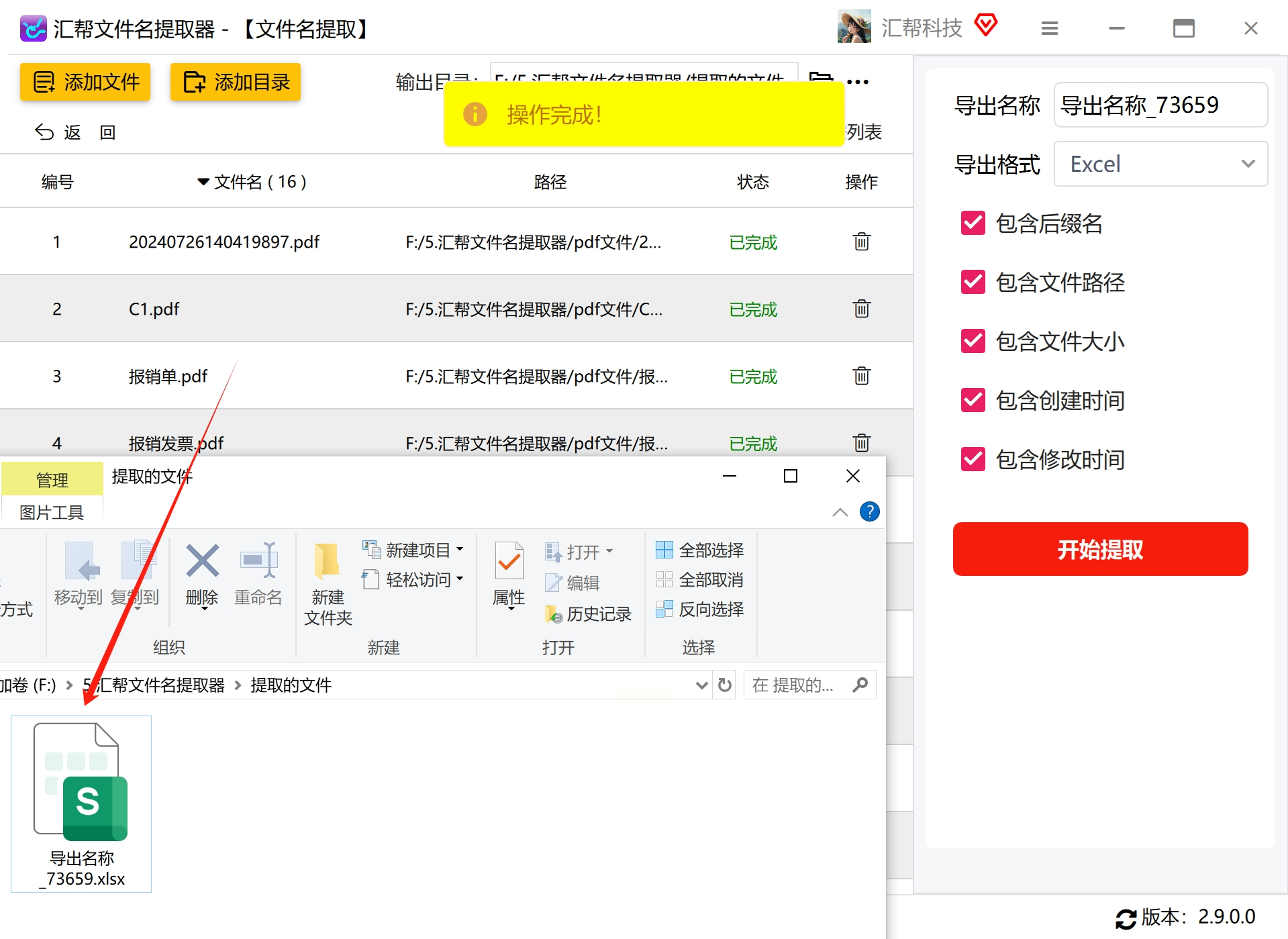
方法二:使用Python脚本提取(适合有编程基础的用户)PDF文件名
1. 确保电脑已安装Python环境(推荐Python 3.7+版本)
2. 了解基本的文件路径操作(如C:\Users\Documents\PDFs)
操作步骤
1. 创建Python脚本:
```python
import os
# 设置目标文件夹路径,注意用英文引号和双反斜杠
folder_path = r"C:\Users\YourName\Documents\PDF_Files"
# 初始化列表存储文件名
pdf_files = []
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
# 检查文件是否以.pdf结尾(区分大小写)
if filename.lower().endswith(".pdf"):
pdf_files.append(filename)
# 将结果写入文本文件
with open("pdf_list.txt", "w", encoding="utf-8") as file:
for name in pdf_files:
file.write(name + "\n")
print(f"共提取{len(pdf_files)}个PDF文件,已保存至pdf_list.txt")
```
2. 运行脚本:
- 将上述代码保存为`extract_pdf.py`
- 打开命令提示符(Win+R输入cmd),执行:`python extract_pdf.py`
- 脚本会在同目录生成`pdf_list.txt`,包含所有PDF文件名
3. 转换为Excel格式:
- 打开Excel,粘贴文本文件内容
- 使用"数据"选项卡中的"分列"功能,按空格或制表符分隔
- 保存为.xlsx格式,即可添加到表格中
方法三:使用在线工具页可以提取PDF文件名
1. 选择在线工具
2. 上传文件:
- 点击"选择文件"或直接拖拽PDF文件到上传区
- 支持同时上传多个文件(最多200MB)
3. 提取并导出:
- 点击"提取文件名"按钮(约需5-10秒)
- 选择导出格式(Excel/CSV/TXT)
- 下载生成的文件,直接打开即可使用
通过以上方法,您可以轻松解决PDF文件管理中的文件名提取难题。小白的话建议优先尝试专业软件(方法一),熟练后再根据需求学习Python脚本,逐步建立自己的文件管理体系。记住:好的工具和方法不仅能节省时间,更能让工作更有条理、更专业。
