

快速提取大量PDF文件名称并导出至Excel的方法!在日常工作和学习中,我们经常会遇到需要整理和管理大量PDF文件的情况。手动复制粘贴文件名不仅耗时且容易出现错误。幸运的是,通过使用专门的软件或编写简单的脚本程序,我们可以高效地批量获取和导出PDF文件名称至Excel格式,从而提升处理效率、减少人为错误。

方法一:利用“汇帮文件名提取器”快速提取
#步骤1:下载并安装软件
首先,在互联网上搜索并找到“汇帮文件名提取器”,完成其在电脑上的下载和安装。这是一款专门用于批量提取文件名的工具,适用于各种需求。
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
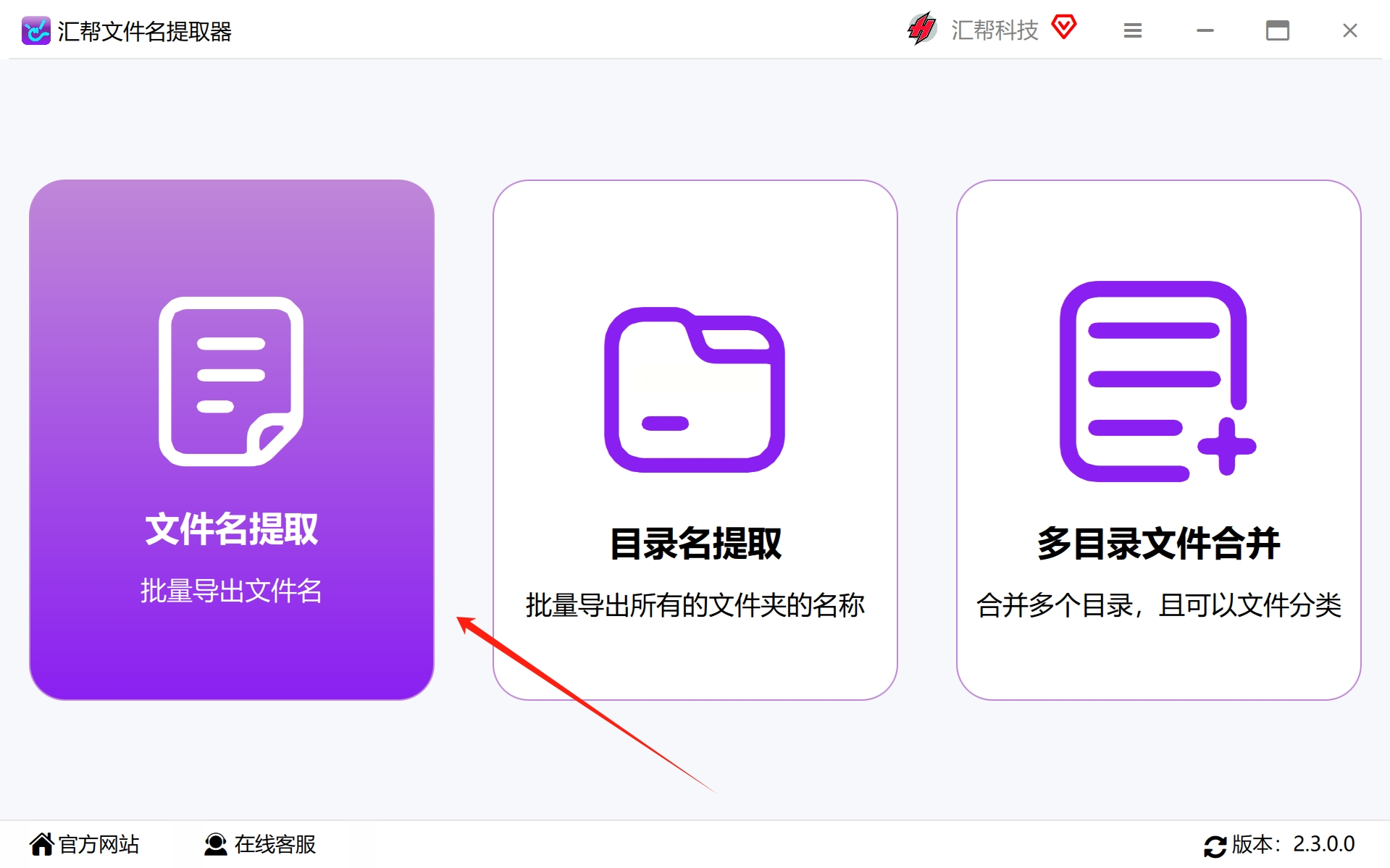
#步骤2:启动及选择功能选项
打开软件后,按照提示进行设置。选择“文件名提取”功能,这是处理PDF文件名称提取的核心步骤。
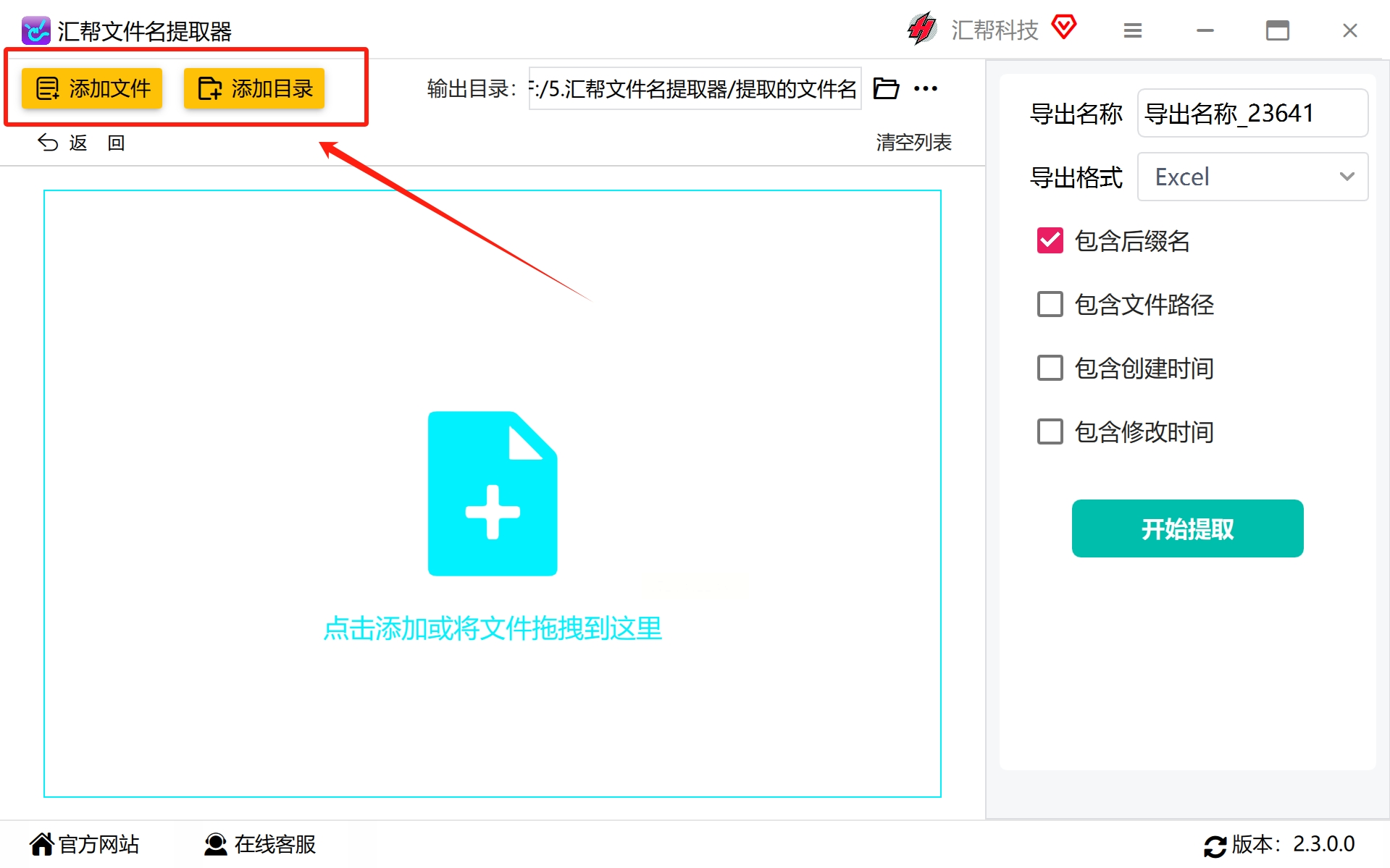
#步骤3:添加PDF文件
通过点击“添加文件”或“添加目录”的按钮,可以选择你希望批量提取文件名的PDF文件所在的文件夹。这样做可以一次选中并处理多个文件,无需逐一操作。
#步骤4:设置导出名称和格式
根据需求自定义导出名称(如果需要),设置导出为的文件类型。在这里选择“Excel”格式作为例子,这样便于进一步的数据分析或集成到工作流程中。
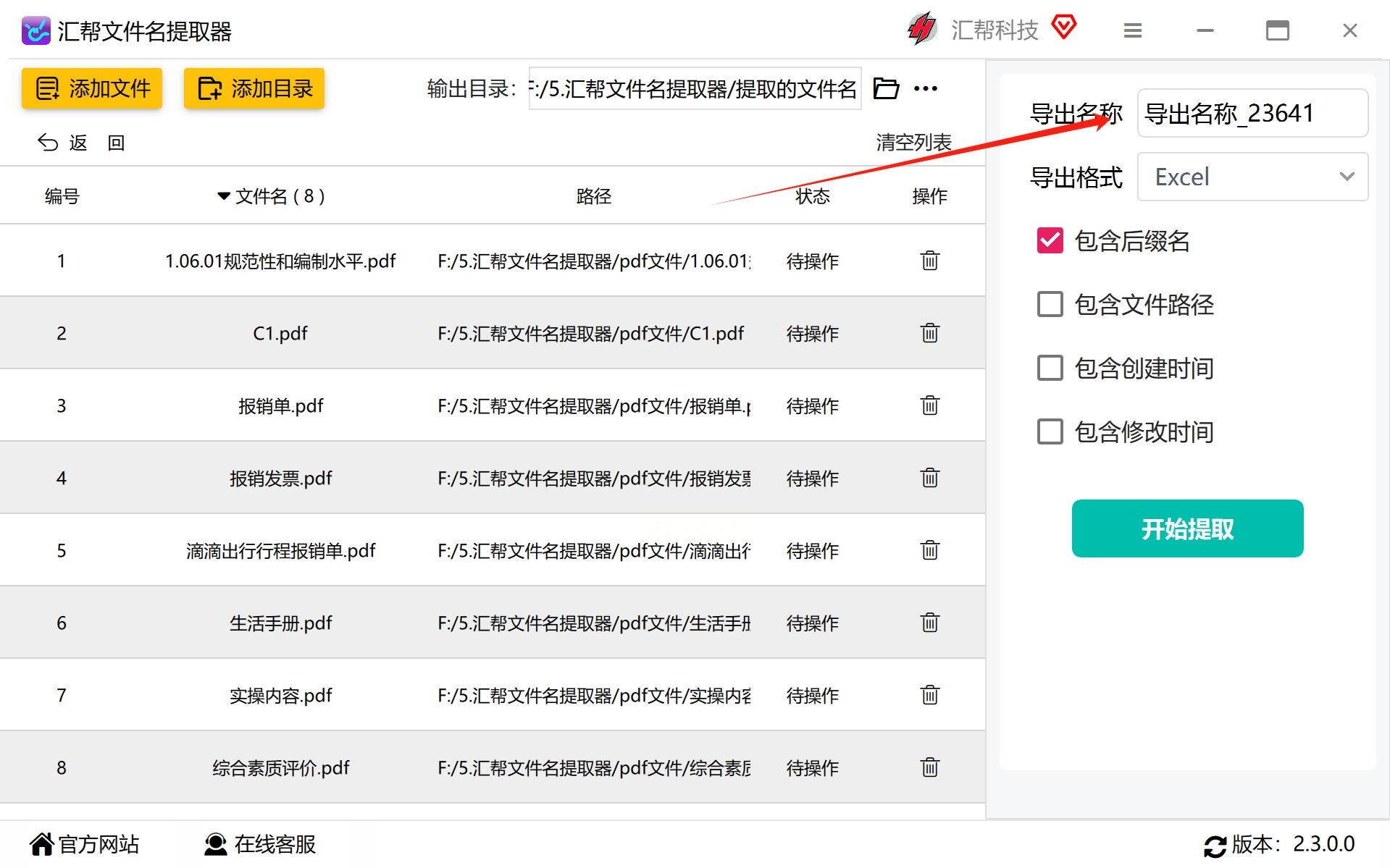
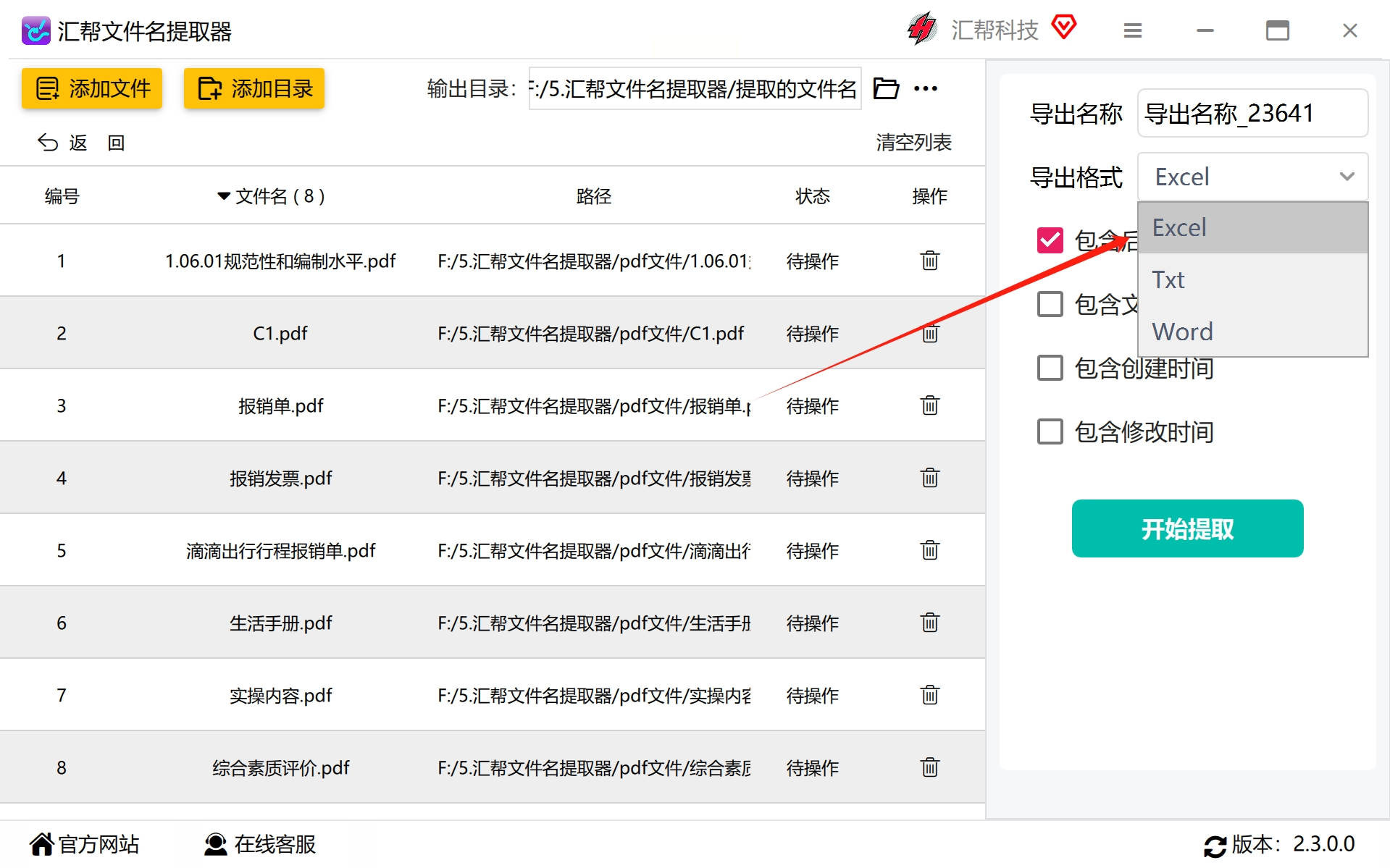
#步骤5:提取元素配置与开始操作
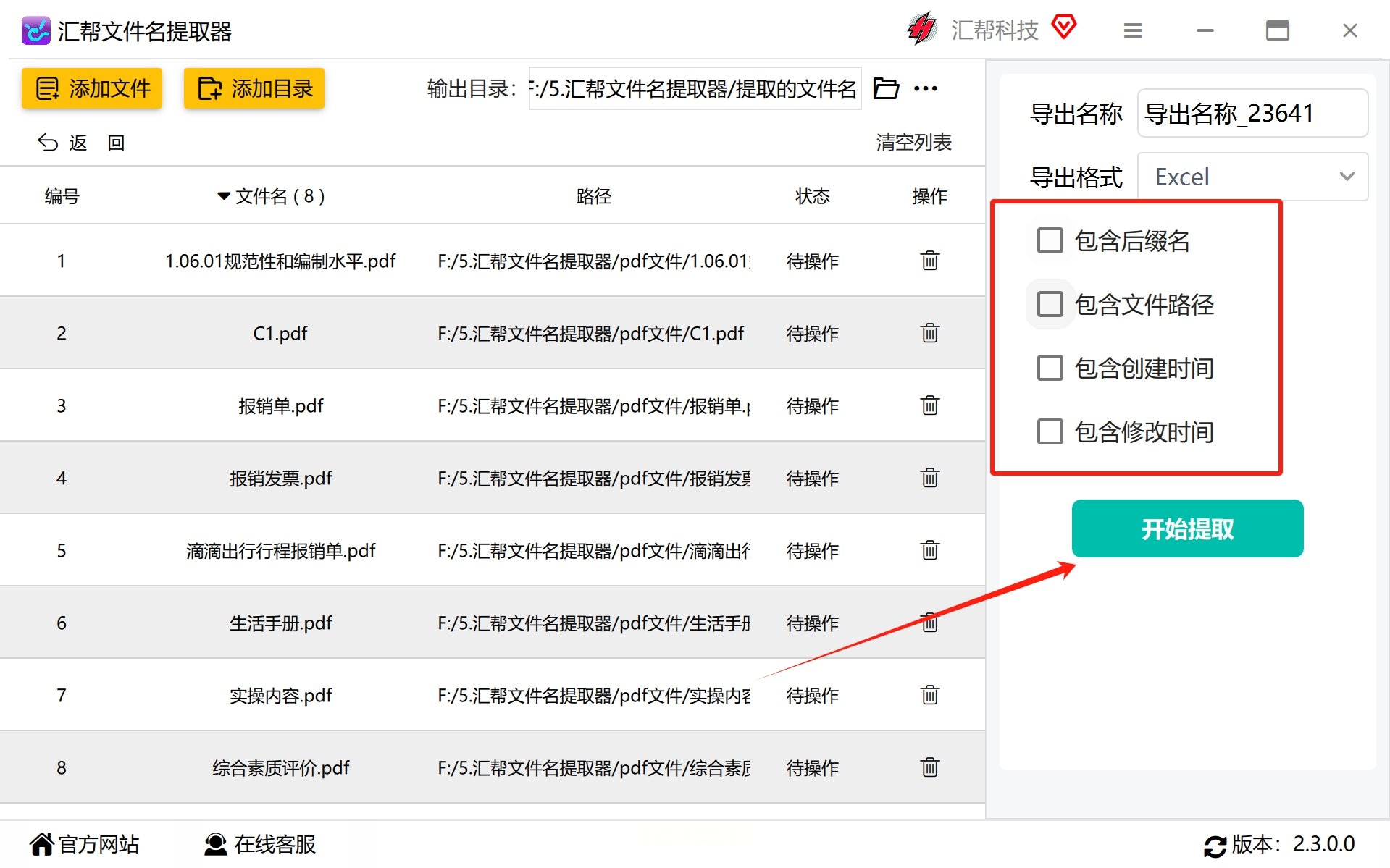
选择你希望提取的信息,如文件名、路径等,然后点击“开始提取”。这个过程可以自动运行,无需持续监控。
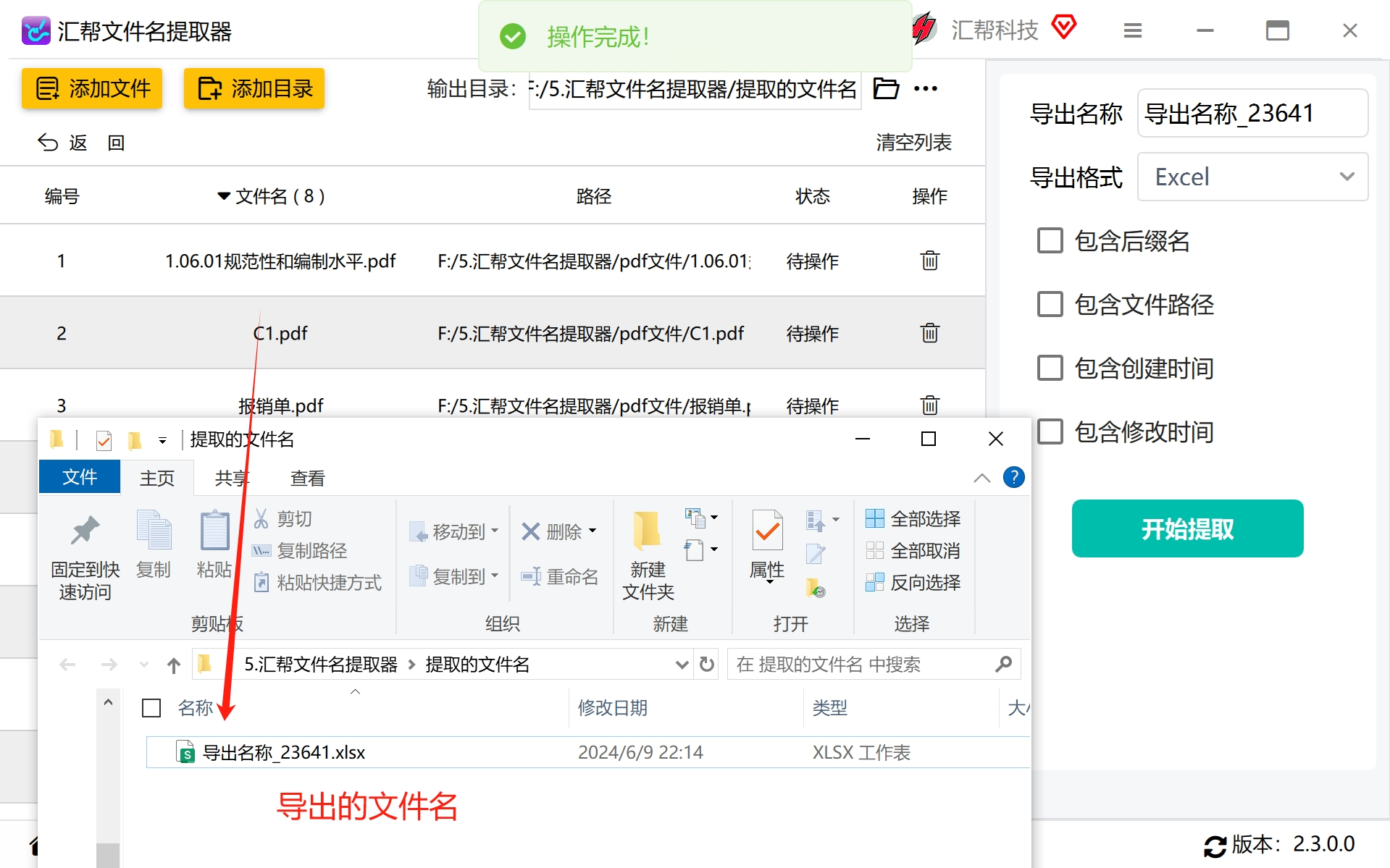
#步骤6:查看和使用导出结果
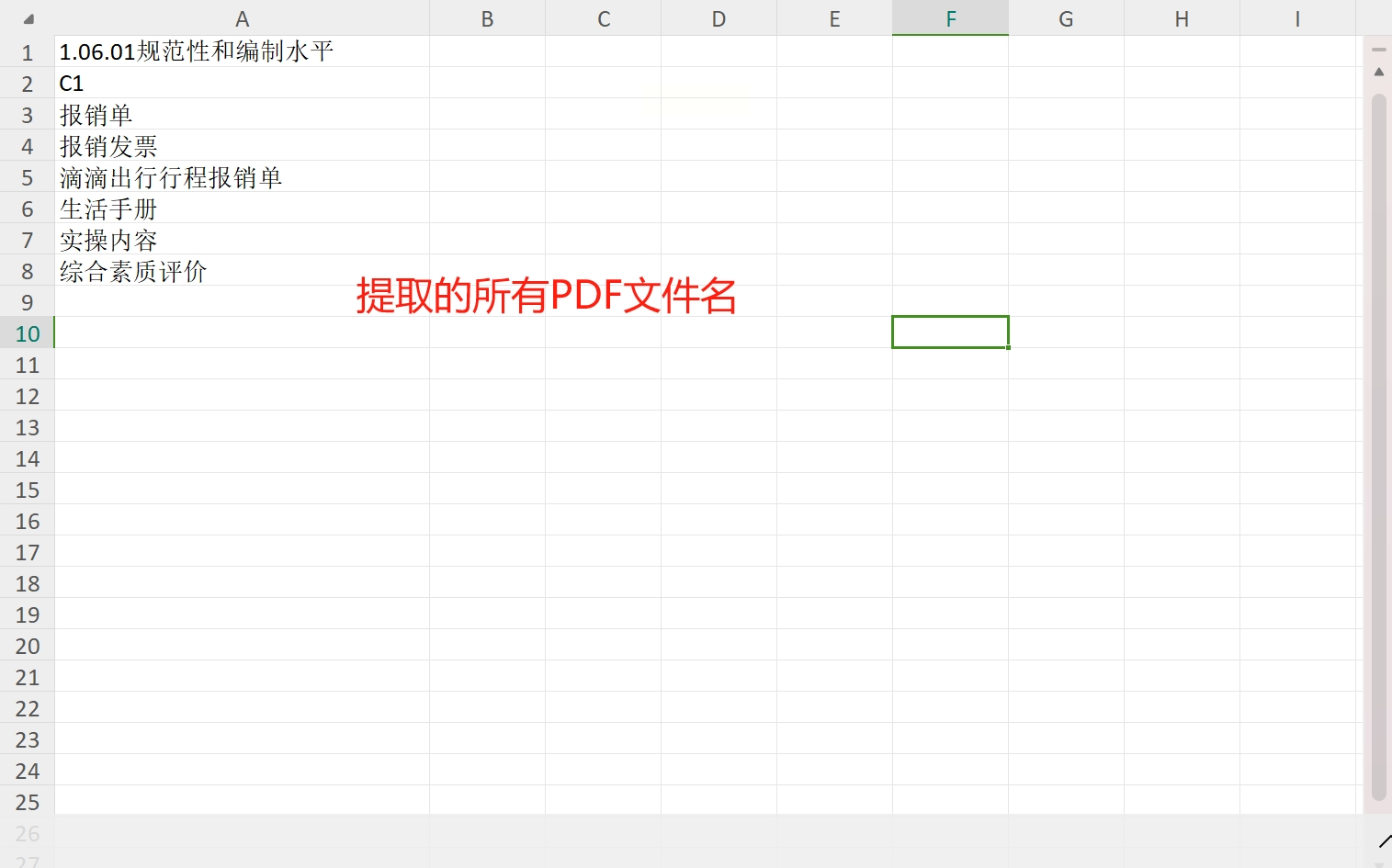
执行完成后,系统会提示完成,并将数据保存在预设的输出目录中。打开生成的Excel文件,可以看到每个PDF文件的名称已整理清晰列于其中。
方法二:编写简单的脚本程序
如果你对编程有基础了解,可以使用Python等语言结合“os”和“glob”模块来自动化处理这个问题。下面是一个简单的Python脚本示例:
```python
import os
import pandas as pd
# 定义要查找的文件夹路径
folder_path = "/path/to/your/folder"
file_extension = "*.pdf"
# 从指定路径获取所有PDF文件名,并保存到列表中
file_names = [os.path.splitext(os.path.basename(file))[0] for file in glob.glob(os.path.join(folder_path, file_extension))]
# 将列表转换为DataFrame并导出至Excel文件
df = pd.DataFrame({'File Names': file_names})
df.to_excel('output_file.xlsx', index=False)
print("CSV file extraction complete!")
```
通过使用专业软件或编写脚本程序,我们可以实现从大量PDF文件中快速提取和整理文件名称的过程。这种方法不仅节省了人工操作的时间,还降低了出错的可能性,提高了工作效率。无论是对于个人的日常任务还是团队中的项目管理,批量处理PDF文件时采用这些自动化方法都是非常实用且高效的选择。
