

在日常工作和生活中,我们经常需要处理大量的文件和文件夹。随着时间推移,文件数量不断积累,文件夹结构也变得越来越复杂。很多时候,我们为了方便分类,会创建多层嵌套的文件夹,但随着时间的推移,这种结构反而成为我们快速访问文件的障碍。想象一下这样的场景:你需要查找一份半年前的项目资料,却不得不在层层嵌套的文件夹中逐级点击;或者你需要整理从多个同事那里收集来的文件,每个人都有自己的文件夹结构,导致最终汇总时文件分散在数十个不同的子文件夹中。这些情况不仅降低了工作效率,还增加了文件管理的复杂度。
批量去掉外层文件夹的需求,正是源于这种实际的文件管理困境。当文件夹嵌套过深时,即使我们知道文件存在,也需要花费大量时间在文件夹层级间导航。更麻烦的是,某些应用程序或系统对文件路径长度有限制,过深的文件夹结构可能导致无法正常访问文件。此外,在备份文件时,多层文件夹结构可能会使备份过程变得缓慢且复杂;在共享文件时,接收方也需要花费时间理解你的文件夹组织结构。所以去除文件夹的层级把里面的文件提取到一个文件夹中就可以派上用场了。
怎么取消多余的文件夹分级?快速提取多层文件夹里文件的方法

方法一:使用“汇帮文件名提取器”软件的文件夹合并功能来去除文件夹的各个层级
软件名称:汇帮文件名提取器
下载地址:https://www.huibang168.com/download/wGi5oWZ2FL8S
1. 准备工作
可以将整个文件夹复制到另一个位置,这样即使操作中出现问题,也能快速恢复原始状态。同时,关闭可能正在访问这些文件夹的其他应用程序,避免文件被占用导致操作失败。
2. 软件安装与启动
首先需要获取并安装文件夹管理软件。本文以“汇帮文件名提取器”为例,您也可以选择其他具有类似功能的软件。安装完成后,双击软件图标启动程序。首次使用时,可以花几分钟熟悉界面布局和各个功能区域的位置。
3. 选择合并功能
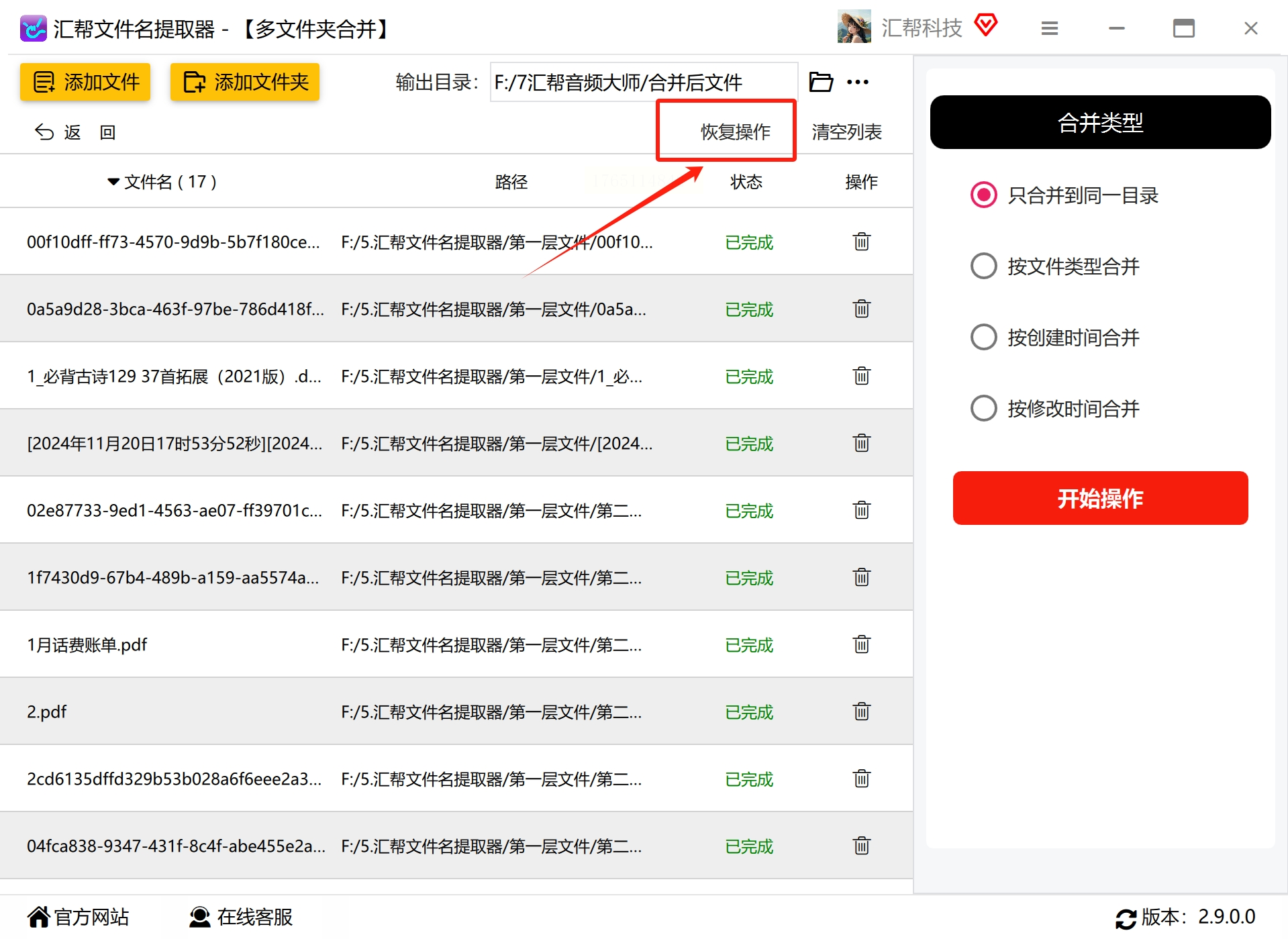
在软件主界面中,找到并点击“多文件夹合并”功能选项。这个功能专门设计用于处理多个文件夹中的文件合并任务。进入功能界面后,您会看到添加文件夹、设置输出目录等选项。
4. 添加待处理的文件夹
点击“添加文件夹”按钮,在弹出的文件选择对话框中,导航到包含外层文件夹的目录。您可以一次选择多个顶层文件夹,也可以选择单个包含多个子文件夹的父级文件夹。另一种便捷的方式是直接将这些文件夹从文件资源管理器拖拽到软件界面中。

5. 设置输出位置
指定一个输出目录作为处理后文件的存储位置。建议选择一个空文件夹或新建一个文件夹,避免与现有文件混淆。清晰的输出路径有助于后续快速找到处理完成的文件。
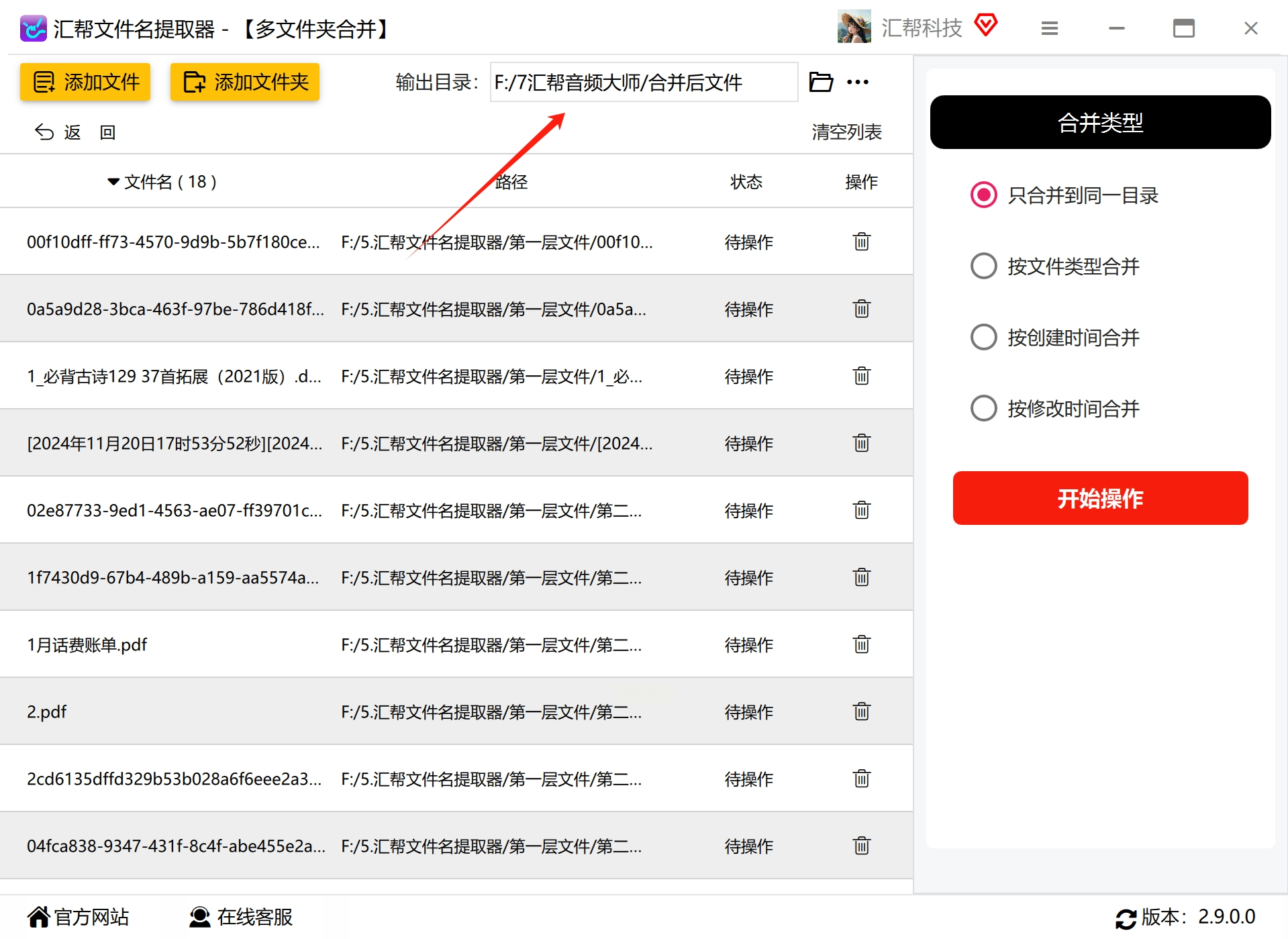
6. 配置合并选项
在右侧的设置区域,找到“合并类型”选项。对于去掉外层文件夹的需求,选择“只合并到同一目录”即可。软件通常还提供其他合并方式,如按文件类型、创建时间或修改时间进行合并,您可以根据实际需求选择。确认设置无误后,点击“开始操作”按钮。
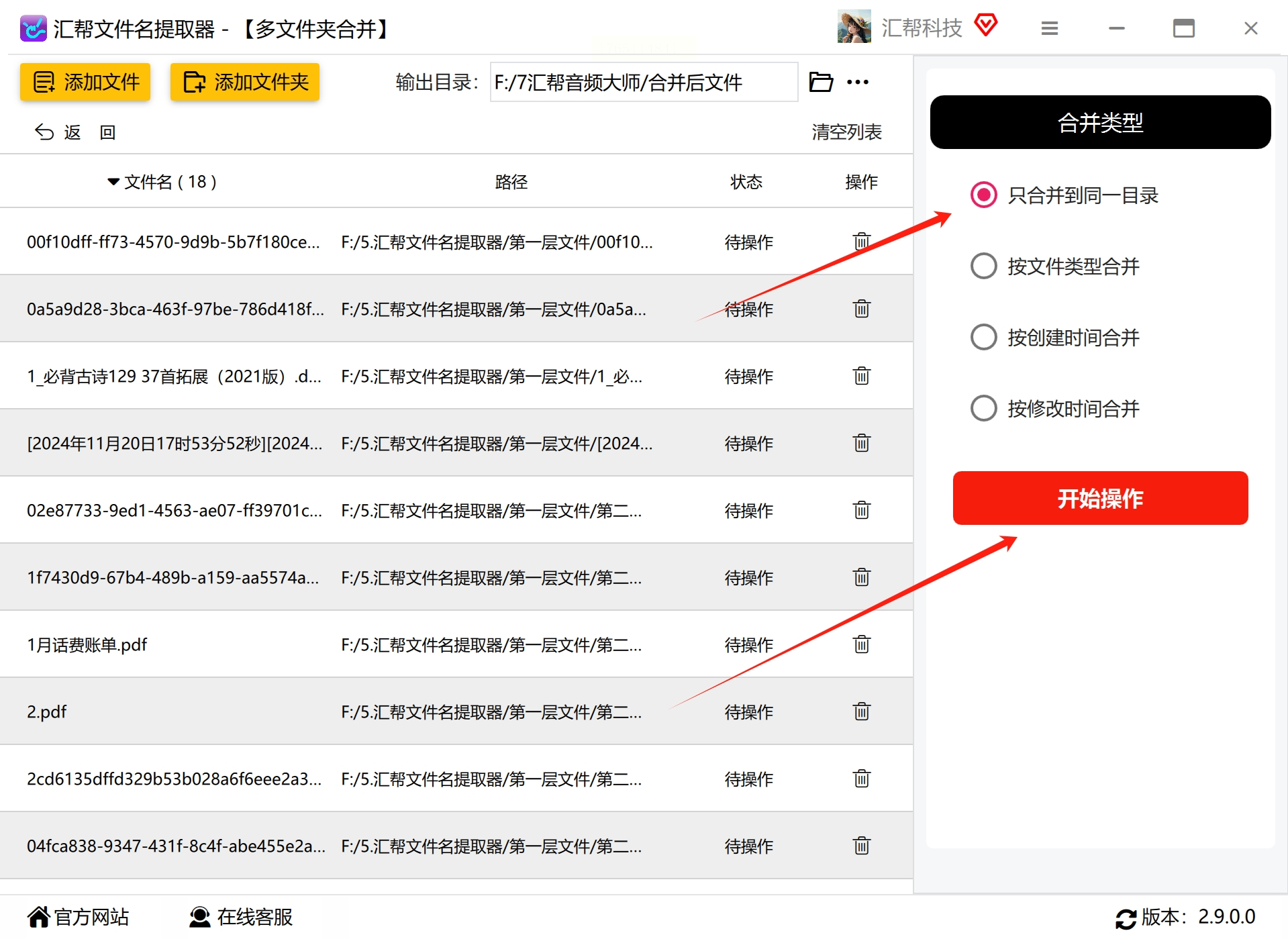
7. 等待处理完成
软件开始处理文件,处理时间取决于文件数量和大小。在状态栏或进度条中可以查看处理进度。请耐心等待,不要中途关闭软件或进行其他文件操作。
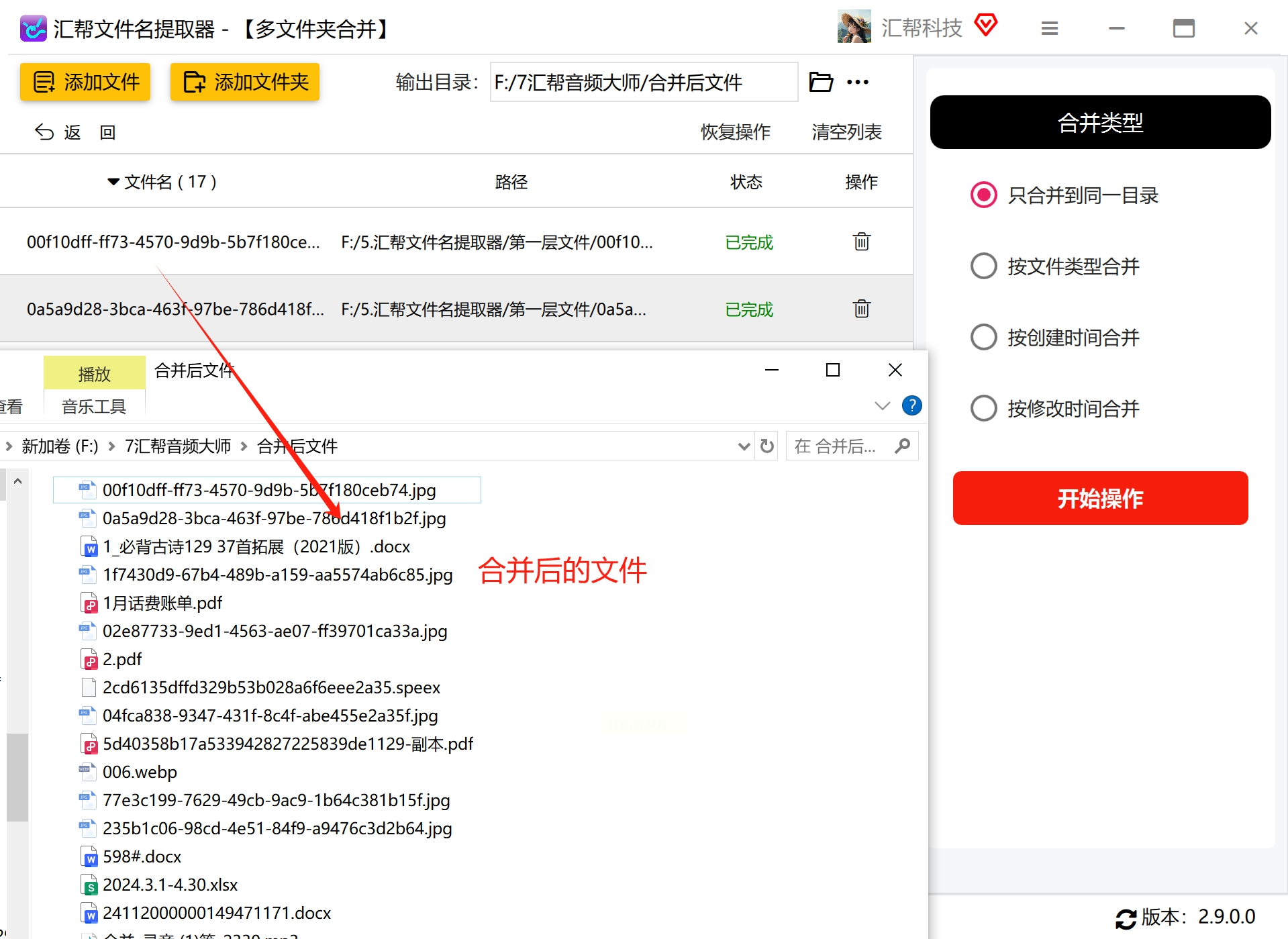
8. 验证处理结果
处理完成后,打开设置的输出目录,检查文件是否已从各子文件夹中提取出来并合并到同一目录下。同时检查文件数量是否与预期一致,重要文件是否完整无损坏。
9. 恢复选项的使用
如果对处理结果不满意,软件通常提供“恢复操作”功能,可以将文件恢复到原始位置。但请注意,此功能一般只能恢复当次操作,且需要在未进行其他文件操作前使用。
方法二:编写批处理脚本自动处理
对于有一定技术基础的用户,使用脚本批量处理文件夹可以提供更高的灵活性和自动化程度。这种方法特别适合需要定期执行相同操作,或处理规则复杂的场景。
操作步骤:
1. 环境准备
首先确保计算机上安装了Python环境。可以从Python官网下载并安装最新版本。安装时记得勾选“Add Python to PATH”选项,这样可以在命令行中直接调用Python。
2. 创建脚本文件
打开文本编辑器(如记事本、VS Code等),新建一个文件。将以下代码复制到文件中:
```python
import os
import shutil
def flatten_folders(target_path):
"""
将目标路径下所有子文件夹中的文件移动到目标路径,
然后删除空的子文件夹
"""
# 检查目标路径是否存在
if not os.path.exists(target_path):
print(f"错误:路径 '{target_path}' 不存在")
return
# 获取目标路径下的所有项目
items = os.listdir(target_path)
# 筛选出文件夹
folders = [item for item in items
if os.path.isdir(os.path.join(target_path, item))]
print(f"找到 {len(folders)} 个文件夹需要处理")
moved_files_count = 0
# 遍历每个文件夹
for folder in folders:
folder_path = os.path.join(target_path, folder)
try:
# 获取文件夹中的所有文件
files = os.listdir(folder_path)
# 移动每个文件
for file in files:
src_path = os.path.join(folder_path, file)
dst_path = os.path.join(target_path, file)
# 处理文件名冲突
base_name, extension = os.path.splitext(file)
counter = 1
while os.path.exists(dst_path):
new_name = f"{base_name}_{counter}{extension}"
dst_path = os.path.join(target_path, new_name)
counter += 1
# 移动文件
shutil.move(src_path, dst_path)
moved_files_count += 1
# 删除空文件夹
os.rmdir(folder_path)
print(f"已处理文件夹: {folder}")
except Exception as e:
print(f"处理文件夹 '{folder}' 时出错: {str(e)}")
print(f"处理完成!共移动 {moved_files_count} 个文件")
if __name__ == "__main__":
# 设置要处理的文件夹路径
target_directory = "请输入您的目标文件夹完整路径"
# 确认操作
confirm = input(f"即将处理文件夹: {target_directory}\n是否继续?(y/n): ")
if confirm.lower() == 'y':
flatten_folders(target_directory)
else:
print("操作已取消")
```
3. 修改目标路径
在代码中找到`target_directory`变量,将其值修改为您要处理的实际文件夹路径。路径应使用双反斜杠或正斜杠,例如:`"C:\\Users\\用户名\\文档\\待处理文件夹"`或`"C:/Users/用户名/文档/待处理文件夹"`。
4. 保存脚本文件
将文件保存为`.py`扩展名,例如`flatten_folders.py`。选择一个容易找到的位置保存,如桌面或文档文件夹。
5. 首次测试运行
在运行脚本前,建议先在一个包含测试文件夹的目录中尝试。创建一些测试文件夹和文件,确保脚本按预期工作。打开命令行工具(CMD或PowerShell),导航到脚本所在目录,运行命令:`python flatten_folders.py`
6. 脚本执行过程
脚本启动后,会显示找到的文件夹数量并要求确认。输入`y`继续,脚本将开始处理。处理过程中会显示每个文件夹的处理状态。如果遇到文件名冲突,脚本会自动为文件添加数字后缀。
7. 处理结果验证
脚本运行完成后,检查目标文件夹。所有子文件夹中的文件应已被移动到目标文件夹根目录,空的子文件夹已被删除。检查文件数量是否完整,重要文件是否完好。
8. 错误处理与调试
如果脚本运行出错,仔细阅读错误信息。常见问题包括:路径错误、文件被其他程序占用、权限不足等。根据错误提示调整脚本或系统设置后重试。
文件管理是现代数字生活中不可或缺的技能,而批量处理文件夹的能力则是这一技能的重要组成部分。面对日益增长的数字资料,高效的文件整理方法不仅能节省时间,还能减少工作压力,提高整体工作效率。
学习这些方法的目的不仅仅是完成眼前的任务,更是培养系统性解决问题的思维。在实际工作中,我们遇到的问题可能比单纯的“去掉外层文件夹”更复杂,但解决问题的逻辑是相通的:分析需求、评估选项、选择方法、谨慎执行、验证结果。
